处理海量数据:列式存储综述(系统篇)

在上一篇文章《处理海量数据:列式存储综述(存储篇)》 中,我们介绍了几种 Apache ORC、Dremel 等几种典型列式存储的数据组织格式。实践中,很多数据系统构建在 HDFS 等分布式文件系统之上,使用这些规范的格式保存数据,方便各方的业务进行分析查询。
本文将介绍若干个典型的列式存储数据库系统。作为完整的 OLAP 或 HTAP 数据库系统,他们大多使用了自主设计的存储方式,运行在多台机器节点上,使用网络进行通讯协作。
C-Store (2005) / Vertica
大多数 DBMS 都是为写优化,而 C-Store 是第一个为读优化的 OLTP 数据库系统,虽然从今天的视角看它应当算作 HTAP 。在 ad-hoc 的分析型查询、ORM 的在线查询等场景中,大多数操作都是查询而非写入,在这些场景中列式存储能取得更好的性能。像主流的 DBMS 一样,C-Store 支持标准的关系型模型。
在上一篇文章中,我们已经介绍了 C-Store 特有的 projection 数据模型。这里只做一个简单的回顾:每个 projection 可以包含一个或多个列,完整的表视图需要通过若干 projection JOIN 得到。Projection 水平拆分成若干 segments。
C-Store 的设计考虑到企业级应用的使用模式,在优化 AP 查询的同时兼顾了大多数 DBMS 具有的 TP 查询功能。在 ACID 事务方面同样提供了完整的支持,支持快照(snapshot)读事务和一般的 2PC 读写事务。
通常而言,互联网应用对 DBMS 有较高的并发写入需求,对一致性读、分析型查询的需求不那么强烈。而企业级应用(例如 CRM 系统)的并发写入需求不大,但需要对一致性读、分析型查询等。
系统设计
C-Store 将其物理存储也就是每个 projection 分成两层,分别是为写优化的 Writeable Store (WS) 和为读优化的 Read-optimized Store (RS)。RS 即是基线数据,WS 上暂存了对 RS 数据的变更,二者在读取时需要 merge 得到最新的数据。在上一篇文章的 Apache ORC 格式种,我们也看到了类似的做法(基线数据叠加增量数据)。
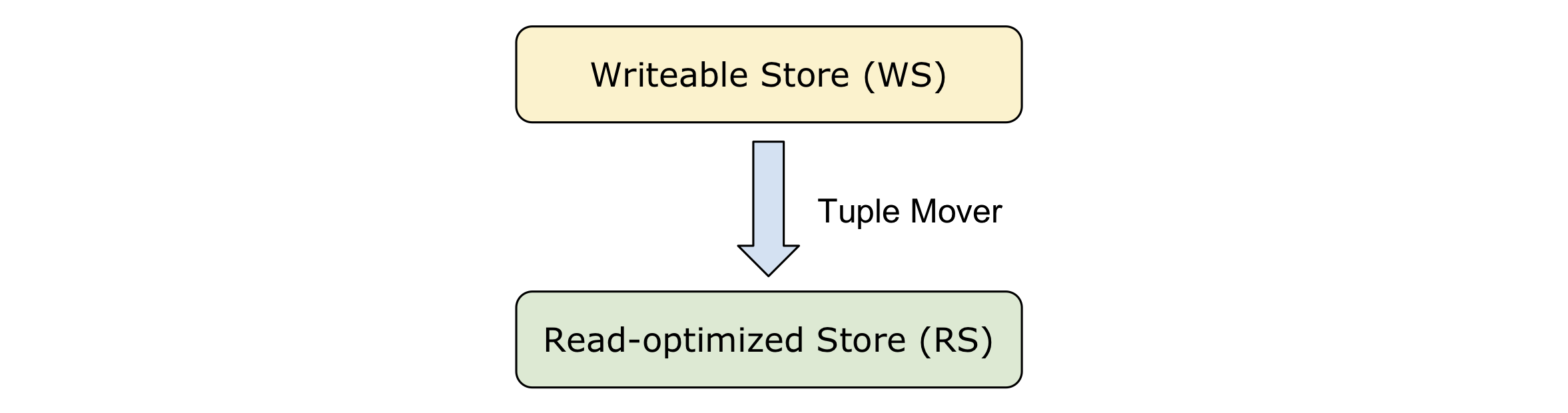
RS 是一个为读优化的列式存储。RS 中采用之前提到的 projection 数据模型,对不同的列采用了不同的编码方式,根据它是否是 projection 的排序列、以及该列的取值个数,来决定采取何种编码方式。
WS 用于暂存高性能的写入操作,例如 INSERT、UPDATE 等。为了简化系统的设计,WS 逻辑上仍然按照 projection 的列式模型存储,但是物理上使用 B 树以满足快速的写入要求。WS 基于 BerkeleyDB 构建。
对于某一列中的某个值 v,会有两个映射关系存在:一是
(storage_key -> v),在 RS 中 storage_key 就是 segment
中的行号,但在 WS 中显式的记录下来;二是
(sort_key -> storage_key),用于满足主键查询的需求。
值得一提的是,WS 是一个 MVCC 的存储——它的每个数据都保存了对应的写入事务编号,同一行可能有多个版本同时存在。而 RS 是没有 MVCC 的,你可以将它看作过去某个时间点的快照。
Tuple Mover 周期性地将 WS 中的数据移动到 RS 中。与大多数 MVCC 系统一样,C-Store 中的更新是通过一个删除加一个插入实现的,Tuple Mover 的主要工作是根据 WS 的数据更新 RS:删掉被删除的行、添加新的行。
事务支持
C-Store 认为大多数事务是只读事务,因此采用了 Snapshot Isolation。C-Store 维护两个全局的时间戳:低水位(Low Water Mark, LWM)和高水位(High Water Mark, HWM),允许用户查询介于二者之间的任意时间戳的 Snapshot。时间戳来自中心化的 Time Authority (TA)。
LWM 对应 RS 即基线数据的版本。Tuple Mover 会保证任何高于 LWM 的修改都不会被移动到 RS 中,因为一旦移动到 RS 也就失去了多版本。
HWM 由中心的 TA 维护,时间被分成固定长度的 epoch。当各个节点确认
epoch e 中开始的写入事务完成时,就会发送一个
Complete(e) 的消息给 TA,当 TA 收集到所有节点的
Complete(e) 将 HWM 置为 e。换句话说,HWM
以前的事务一定是已经完成提交的。
对于读写事务,C-Store 采用了传统的 2PC。
MonetDB (2012) / VectorWise
MonetDB 是一个面向 OLAP 的内存数据。区别于大多数 DBMS 使用的 Valcano 执行模式,MonetDB 使用一种独特的 full materialization 的列式(向量)执行模型,也因此设计了对应的一系列算子以及查询优化器。
BAT Algebra
MonetDB 独有的列式计算是通过 BAT(Binary Association Table)的运算组成的,BAT 之间通过算子产生新的 BAT,最终生成查询结果。每个 BAT 可以简单地理解为一列带有编号的数据 <oid, value>,有些 BAT 来自用户的逻辑表,其他则是运算的结果。每个算子被设计地很紧凑、高效,能充分利用 CPU 流水线的计算能力,这和 CPU 设计的 RISC 思想颇为相似,所以被称为“数据库查询的 RISC 方案”。
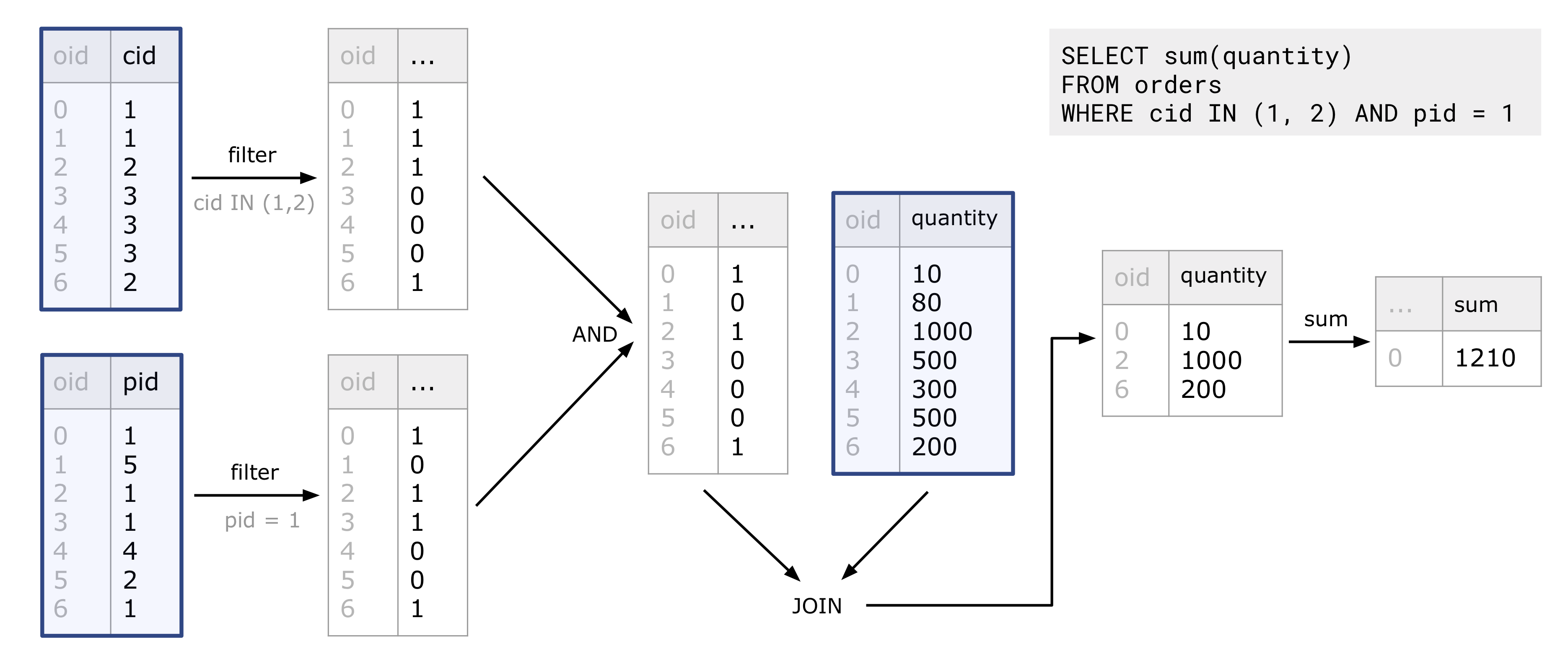
如上图,对于用户一条 SELECT 查询,MonetDB 先将其分解为多次 BAT 的运算,执行计划中的每一步的输入和输出都是 BAT。图中蓝框中为输入的 BAT,其他则是执行产生的运算结果。
MonetDB 的设计决定了它的计算过程十分耗费内存。MonetDB 利用操作系统的 Memory Mapped File 进行内存管理,不使用的页面可以被换出内存,为执行查询腾出空间。但显然这并不是一个彻底的解决方案。
VectorWise 使用类似的向量化执行模型,但它尝试在 full materialization 和 Valcano 模型中间寻求一个平衡——它将整个列划分成较小的 block,对 block 进行上述的 column algebra 计算。
Apache Kudu (2015)
Kudu 是 Cloudera 研发的处理实时数据的 OLAP 数据库。上文提到的 Parquet / ORC 是开源界常用的处理静态数据的方式,为什么说是静态数据呢?因为这些紧凑的格式对数据修改很不友好,且随机读写性能极差,通常只能用于后台 OLAP。
所以我们看到,很多数据系统都采用动态、静态两套数据,例如:把在线业务数据放在 HBase 中,定期通过 ETL 程序产生Parquet 格式文件放到 HDFS 上,再对其进行统计、归档等。这种定期导入的方式不可避免地会带来小时级的延迟,而且,众所周知维护 ETL 代码是一件费时费力的事情。
Kudu 试图在 OLAP 与 OLTP 之间寻求一个平衡点——在保持同一份数据的情况下,既能提供在线业务实时写入的能力,又能支持高效的 OLAP 查询。
Kudu 采用我们熟悉的半关系型模型,允许用户定义 schema,但是目前并不支持二级索引。
事务方面,Kudu 默认使用 Snapshot Isolation 一致性模型。此外,如果用户需要一个更强的一致性保证(例如 read own's writes),Kudu 也允许用户指定特定的时间戳,读取这个时间戳的 snapshot。这项功能被集成在 Kudu 的 API 层面,用户可以方便地获得因果(causality)一致性保证。
系统设计
Kudu 采用了类似 HBase 的 master-slave 架构:中心节点被称作 Kudu Master,数据节点被称作 Tablet Server。一个表的数据被分割成多个 tablets,由它们对应的 Tablet Server 来提供数据读写服务。
与 HBase 相比,中心节点 Kudu Master 除了存放了 Tablet 的分布信息,还身兼了如下角色:
- Catalog 管理:同步各个库、表的 schema 等元信息、负责协调完成建表等 DDL 操作
- 集群协调者:各个 Tablet Server 向其汇报自己的状态、replica 变更等
Kudu 底层数据文件并没有存储在 HDFS 这样的分布式文件系统上,而是基于 Raft 算法实现了一套副本同步机制,保障数据不丢失及高可用性。其中 Raft 算法用于同步数据修改操作的 log,这点和大多数 shared-nothing 架构分布式数据库并无二致。对 Raft 算法有兴趣的同学可以参考原论文。
作为列式 OLAP 数据库,Kudu 的磁盘存储是常见的列式方案,很多地方直接复用了 Parquet 的代码。我们知道,紧凑的列式存储难以实现高效的更新操作。Kudu 为了提供实时写入功能,采用了类似 C-Store 中的方案——在不可变的基线数据上,叠加后续的更新数据。
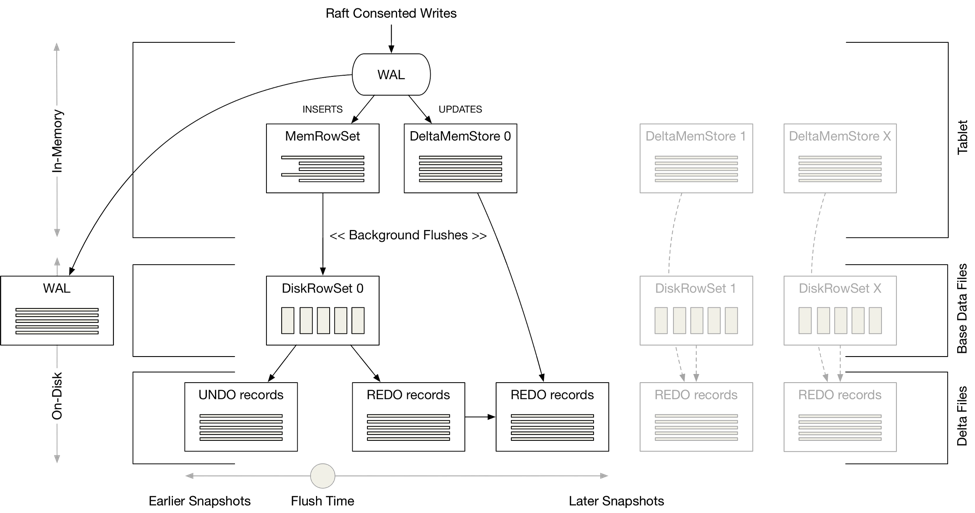
具体来说,Tablet 由 RowSet 组成,而 RowSet 既可以是内存中的 MemRowSet,也可以是存储在磁盘上的 DiskRowSet。一个 RowSet 包含两部分数据:基础数据通常以 DiskRowSet 形式保存在磁盘上;而变更数据先以 MemRowSet 的形式暂存在内存中,后续再异步地刷写到磁盘上。和 C-Store 类似,内存中的数据使用 B 树存储。
与 C-Store 不同的是,Delta 数据并不会立即和磁盘上的基线数据进行合并,而是由后台的 compaction 线程异步完成。值得注意的是,为了保证 compaction 操作不影响过去的 snapshot read,被覆盖的旧数据也会以 UNDO 记录的形式保存在另外的文件中。
PowerDrill (2012)
PowerDrill 是 Google 研发用于快速处理 ad-hoc 查询的 OLAP 数据库,为前端的 Web 交互式分析软件提供支持。PowerDrill 的数据放在内存中,为了尽可能节约空间,PowerDrill 引入一种全新的分区的存储格式,在节省内存占用的同时提供了类似索引的功能,能过滤掉无关的分区、避免全表扫描。
同是 Google 家的产品,和 Dremel 相比,PowerDrill 有以下几点差异:
- 定位不同:Dremel 用于查询“大量的大数据集”(数据集的规模都大,数据集很多),PowerDrill 用于查询“少量的大数据集”(数据集的规模大,但数据集不多)
- Dremel 用全表扫描(full scan)处理查询,而 PowerDrill 对数据做了分区,并能根据查询只扫描用到的分区。
- Dremel 使用类似 Protobuf 的嵌套数据模型;PowerDrill 使用关系模型
- Dremel 的数据直接放在分布式文件系统上,而 PowerDrill 需要一个 load 过程将数据载入内存
数据分区
Ad-hoc 查询常常包含 GROUP BY 子句,在这些 group key
上进行分区,能很好的过滤掉不需要的数据。PowerDrill 需要 DBA
根据自己对数据的理解,选出用于用于分区的一组属性
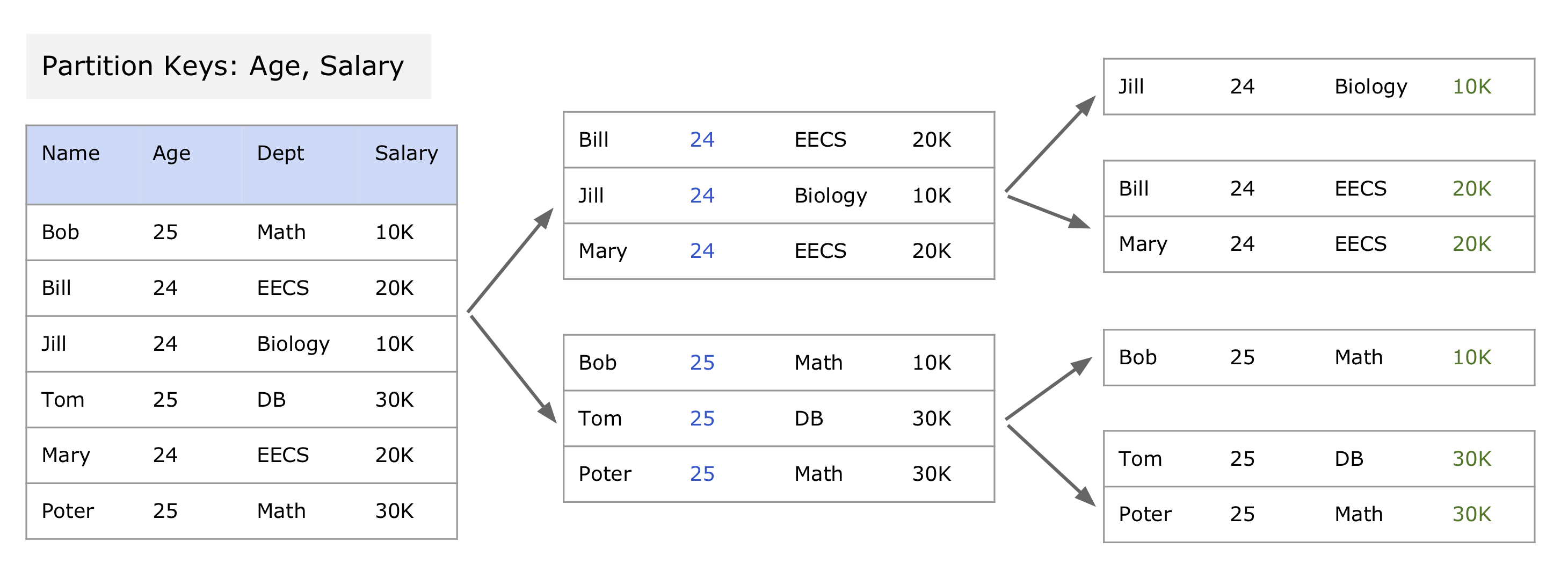
Key1 Key2 Key3 ...(优先级依次递减)。分区是一个递归的过程:一开始把整个数据集视为一个分区(Chunk),如果
Key1 能将数据分开就用 Key1,否则用
Key2、Key3—……直到分区大小小于一个阈值。
以下是一个分区的例子,第一次使用 Age 分区、第二次使用 Salary 分区。
数据结构
PowerDrill 的数据组织以列为单位。对于每个列有一个全局字典表,列的每个分区有一个分区字典表:
- 全局字典表(global dictionary)存储列中所有 distinct 的字符串,按字典顺序排序。字典结构是双向的,既能将 string 映射到 global-id,也能从 global-id 查 string。
- 分区字典表(chunk dictionary)存储一个分区中 chunk-id 到 global-id 的双向映射。相应地,数据列(elements)存储 chunk-id 而不是 global-id。
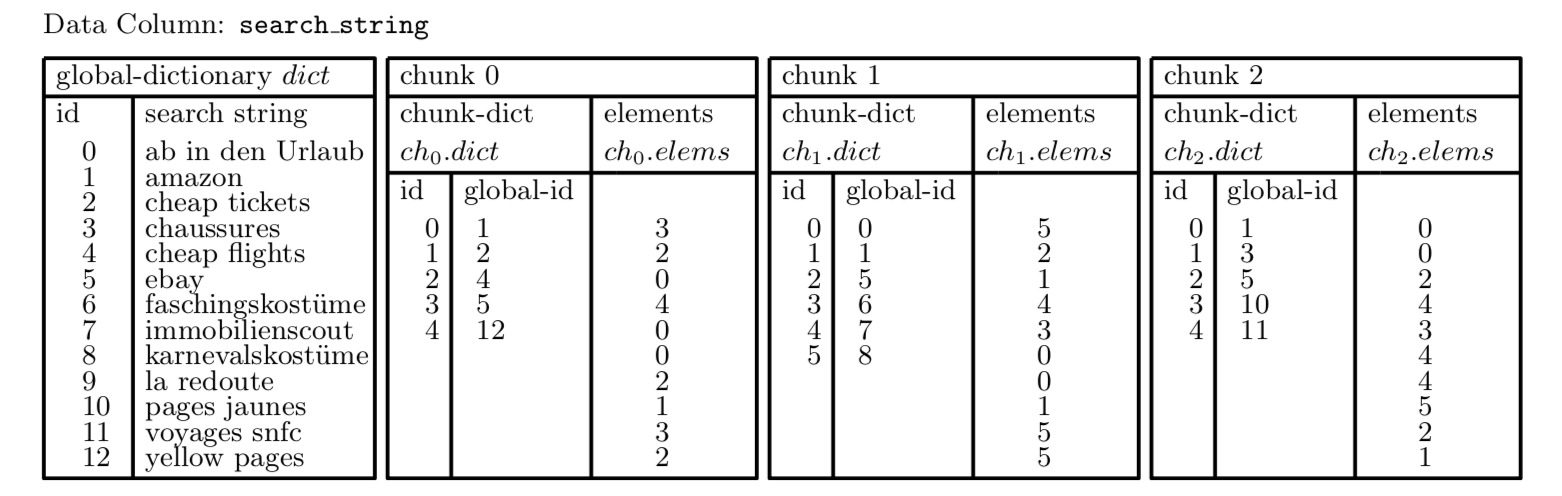
如果要将 chunk 中的一个 element 也就是 chunk-id 还原成数据,第一步需要查分区字典表,得到 global-id;第二步查全局字典表,得到原本的字符串数据。以上图举例而言:
- Chunk 0 存储的 chunk-id 数据
[3, 2, 0, ...] - 根据分区字典表,查出 global-id:
[5, 4, 1, ...] - 根据全局字典表,查出 search string:
['ebay', 'cheap flights', 'amazon', ...]
这样的两层映射保证 chunk-id 尽可能的小,所以可以用更紧凑的编码,比如用 8bit、16bit 整数存储。这不仅能节省空间,也能加快扫描速度。
此外,相同的数据只会在全局字典表中存一份。而且全局字典表中的字符串数据已经被排序,相比不排序,排序后用 Snappy 等算法的压缩比更高。
分区索引
上述的数据结构还有一个额外的好处:它能快速算出某个分区是否包含有用的数据,帮助执行器跳过无关的分区。以下面的 SQL 为例(数据参考上一张图):
1 | SELECT search_string, COUNT(*) as c FROM data |
步骤如下:
- 在
search_string列的全局字典表中查找"[la redoute", "voyages sncf"],得到 global-id[9, 11] - 在各个分区中查找 global-id
[9, 11]: Chunk 0,Chunk 1 中都没有找到,所以可以直接跳过;而 Chunk 2 中出现了[11],对应 chunk-id 为[4] - 在 Chunk 2 中的 elements 扫描查出 chunk-id = 4 的元素数量一共有 3
次,作为
COUNT(*)的结果返回。
总结
本文介绍了几个知名的列式存储系统。与上一篇文章不同,本文的系统大多重新设计了存储层。与此同时,系统的复杂性也大大提升。
在构建自己的数据系统时,除了存储方式本身,以下几个地方是着重需要考虑清楚的地方,上述的几个系统也给我们提供了很好的参考:
- 系统需要处理的查询是怎样的模式?C-Store 主要服务于企业级 HTAP 场景,Kudu 在提供 OLAP 查询能力的同时保持了一定的实时写入能力,PowerDrill 着重处理 ad-hoc 的分析型查询。
- 系统如何保证数据的持久性和高可用性?C-Store 在 projection 上保留了一定的冗余,Kudu 用 Raft 协议保持各个副本的数据一致性及可用性,PowerDrill 则直接把数据放在分布式文件系统上,因为不需要对数据作修改。
- 系统提供怎样的数据一致性保证?对于只读的系统来说,这不是个问题。但是一旦支持写入,数据的一致性、事务隔离性都需要精心的考虑和权衡。Kudu 和 C-Store 的 Snapshot Read 实现可作为参考。
References
- C-store: a column-oriented DBMS - M Stonebraker, DJ Abadi, A Batkin, X Chen…
- The Design and Implementation of Modern Column-Oriented Database Systems - D Abadi, P Boncz, S Harizopoulos…
- Kudu: Storage for Fast Analytics on Fast Data - T Lipcon, D Alves…
- Processing a Trillion Cells per Mouse Click - A Hall, O Bachmann…