Daft:Python 原生的分布式查询引擎
![]()
Daft 是一个高性能、分布式的 Python 计算引擎。相比于 Spark,它提供了原生 Python 接口、更好的性能,以及对 AI 和多模态数据的原生支持。
背景:大数据的历史包袱
过去二十年,企业大数据生态基本由 JVM 系工具主导。Hadoop、Hive、Spark 都诞生于那个年代,它们的设计目标是打造高可靠、高性能的面相结构化数据的 SQL 分析引擎。
但时代变了。如今 80% 的 Spark 用户使用 Python(这是 Spark 联合创始人 Reynold Xin 自己说的)。AI/ML 数据工程师的工作语言是 Python,他们处理的数据也不再只是整齐的结构化表格,而是包括图片、视频、向量等等。
一个很大的问题是,当你用 PySpark 时,Python 代码本质上是在“调用”JVM,中间存在大量的序列化/反序列化开销。想在 Spark 里跑一个自定义 Python UDF?那性能会比 Java/Scala 慢上5~10倍。
![PySpark 的一个运行时错误,来自 JVM 的 stacktrace 只会让用户束手无策,截图来自 [5]](/images/daft/pyspark-error.png)
Daft 正是在这个背景下诞生的——它不再是对 Spark 的修补,而是一次为 AI 时代的需求从头设计的分布式查询引擎。
Daft 是什么?
Daft 是一个高性能、分布式的 Python 计算引擎。相比于上个时代统治地位的 Spark 以及 PySpark,Daft 的核心优势在于:原生 Python 接口 + Native Code 的性能(Rust) + 原生 AI 和多模态支持。稍后我们具体展开。
Daft 也有完整的单机支持——并非仅仅是一个 Worker 节点运行那么简单。当你在本地运行 Daft 时,它会使用 Swordfish 引擎,不依赖分布式框架;而在集群模式下,Daft 使用 Ray 作为分布式调度框架,并借助 Ray 的 Shared Object Store 进行节点间数据交换。
使用 Daft DataFrame API 的体验非常接近数据科学家最熟悉的 Pandas:
1 | import daft |
就这几行代码,Daft 完成了读取 S3 上的 Parquet、过滤行、下载 URL 图片、解码图像——全部可以在分布式集群上执行。
Daft 也支持 PostgreSQL 方言的 SQL 查询,用户可以直接用 SQL 来操作数据,这和 DuckDB 非常类似。
架构设计
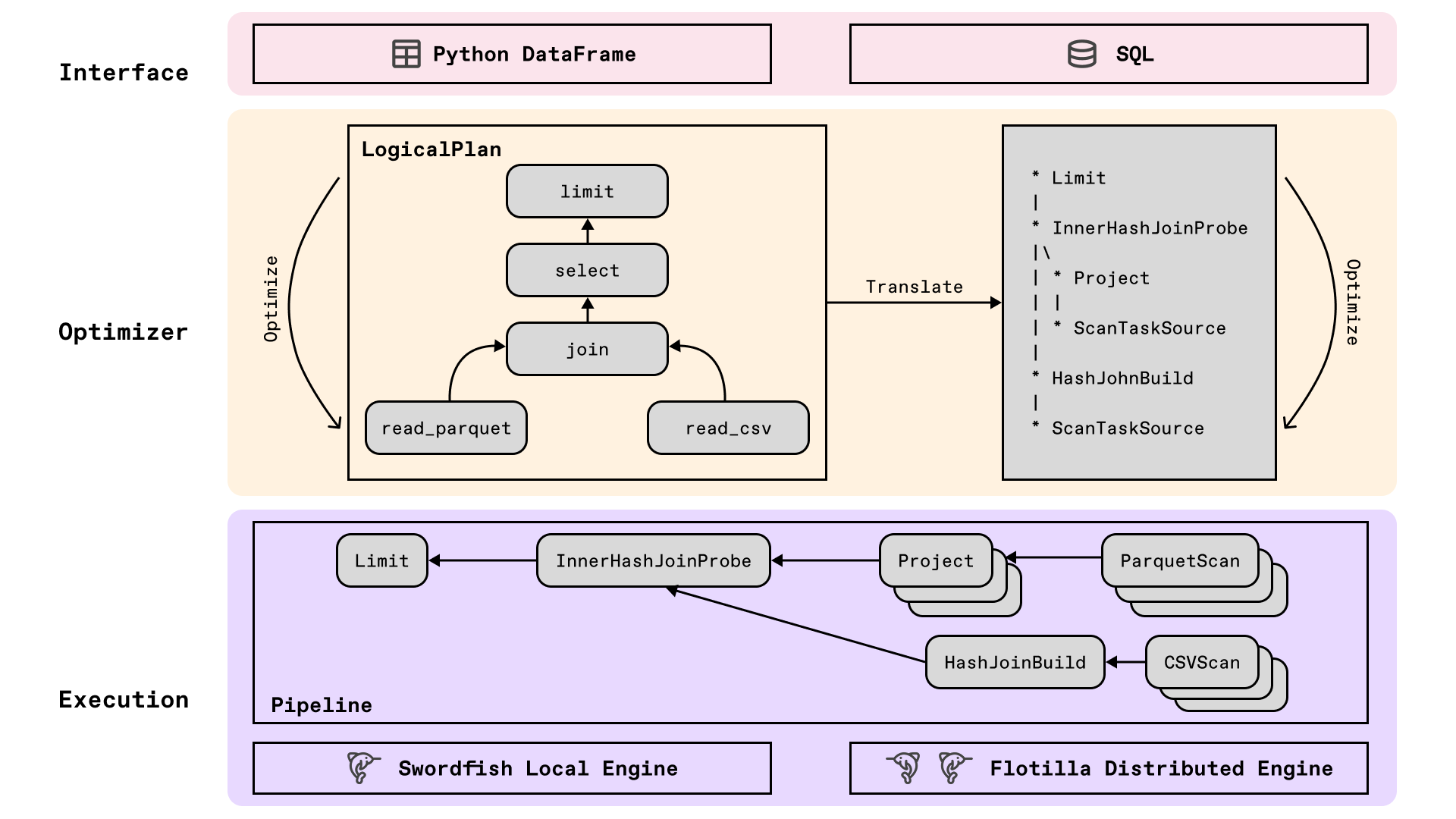
用户接口 & 查询优化
这两层的设计与主流计算引擎(Spark、DuckDB)整体相似,不再赘述,简要说明如下:
- 用户接口(Interface):用户通过 DataFrame API 或者
SQL API 操作数据,所有操作均为惰性的(Lazy)——调用
.filter()或.with_column()时不会立即执行,而是将操作记录进逻辑计划(LogicalPlan)。 - 查询优化(Optimizer):在执行前对 Logical Plan 做各种变换,同样是经典的先 RBO(Rule-Based Optimizer)、再 CBO(Cost-Based Optimizer),完成一系列的包括谓词下推、列裁剪、Limit 下推等 Rule。最后形成 Physical Plan,交给执行器执行。
本地执行引擎:Swordfish
Swordfish 是用 Rust 实现的多线程异步执行引擎。它的核心设计理念是 Morsel-driven 流式处理:数据不再被切成固定大小的分区,而是在运行时动态拆成小块(morsel)流式处理,让 CPU 核心始终保持满负荷。

Swordfish 引擎是 Daft 性能的根基。除了 Native vs JVM 带来的性能提升,Swordfish 还采用了以下几个关键技术:
- Apache Arrow 内存格式 + 零拷贝:列式内存布局让数据在 Daft、PyTorch、NumPy 之间可以直接共享指针,无需序列化复制
- SIMD 向量化:充分利用现代 CPU 的 SIMD 指令集,对数值计算实施批量加速。作为对比,Spark 的 Tungsten 引擎基于 CodeGen JIT 编译,性能已经逐渐落后于向量化加速,Gluten 项目正在尝试引入 Velox 引擎来解决这个问题,但目前还处于早期阶段。
- Morsel-driven 流式执行:本地执行时以小块(morsel)为单位动态调度,避免大分区带来的内存峰值,也使 pipeline 中各算子可以真正并行流水
- 高性能异步 I/O:基于 Rust tokio 异步运行时的 S3/GCS 下载器,官方声称是业界最快的对象存储读取实现。
分布式执行引擎:Flotilla
当数据规模超出单机极限,切换到 Flotilla(代码中也称为 Ray Runner)只需一行代码:
1 | daft.context.set_runner_ray(address="ray://my-cluster:10001") |
Flotilla 采用经典的 Driver/Worker 架构:集群每个节点启动一个 Swordfish Worker,充分利用节点全部资源(CPU、GPU、内存、磁盘、网络);Driver 上的 Flotilla Scheduler 负责任务分发、进度监控,并根据数据 locality 和负载均衡决策调度。
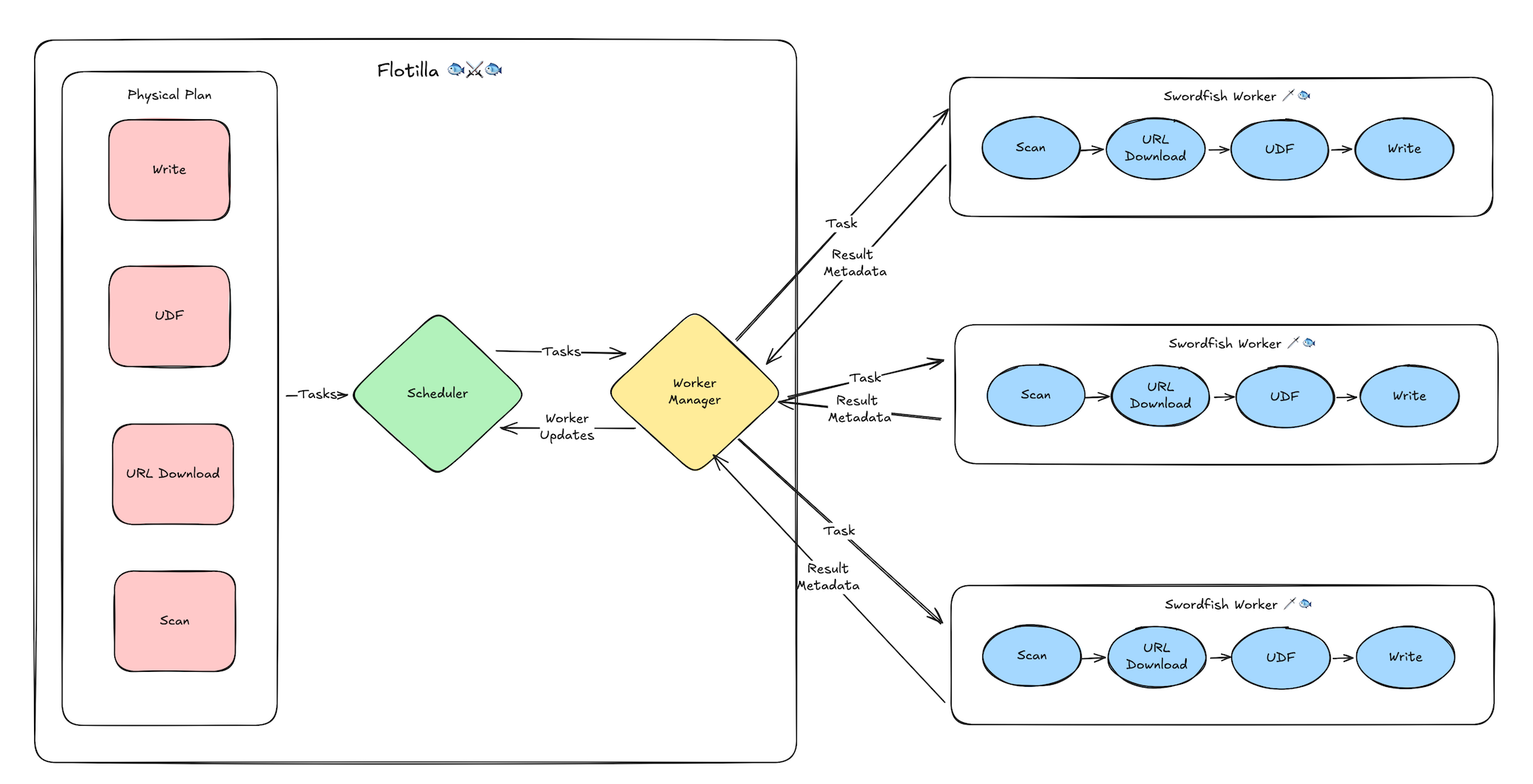
对于需要跨节点数据移动的操作,Flotilla 提供两种 shuffle 机制:
- Ray Object Store Shuffle:数据可放入内存时优先使用,简单高效,Ray 负责数据传输和内存管理(spill 等)
- Flight Shuffle(Beta):基于 Apache Arrow Flight RPC,支持落盘(NVMe)、二进制传输、压缩和多线程并行
Daft vs Spark
| Apache Spark | Daft | |
|---|---|---|
| 用户接口 | DataFrame + SQL | DataFrame + SQL |
| 核心语言 | JVM(Scala & Java) | Python 接口 + Rust 后端 |
| Python 支持 | PySpark,有 JVM 序列化和调用开销 | Python 原生,无额外开销 |
| 执行引擎 | Tungsten(JIT 编译) | Rust + SIMD 向量化 |
| 内存结构 | UnsafeRow 紧凑行式结构 |
Apache Arrow 列式内存结构 |
| 分布式框架 | Spark standalone / YARN / K8s | Ray |
| 多模态数据 | - | 原生支持图片、视频、向量等多模数据 |
关键差异:Python UDF
对 AI/ML 场景来说,Python UDF 是不可或缺的,而这也是 PySpark 最被诟病的地方:
1 | # PySpark UDF 需要序列化 Python 对象到 JVM,再反序列化 |
而 Daft 的 Python UDF 完全没有这样的问题:
1 | # Daft UDF 直接在 Python 进程中运行,无任何跨进程开销 |
Daft vs 其他竞品
- Daft vs Polars: Polars 是另一个 Rust 实现的 DataFrame 库,性能极佳,但仅支持单机。Daft 可以理解为分布式的 Polars + 多模态支持 + 补全了 SQL 查询优化能力。
- Daft vs Dask: Dask 是 Python 原生的分布式计算框架,但它本质上是 Pandas 的并行包装,性能受限于 Pandas,且没有查询优化器。
- Daft vs Ray Data: Ray Data 是 Ray 生态内的数据处理组件,设计比较简单,数据 shuffle 需要用户自行编程解决,也没有查询优化器。
- Daft vs DuckDB: DuckDB 是一个嵌入式分析数据库,单机性能极佳,但不支持分布式。Daft 则是为分布式场景设计的,同时也提供了单机模式。
- Daft vs Smallpond: Smallpond 是 DeepSeek 开源的分布式数据处理框架,它的思路是用 DuckDB 作为单机算子,基于 Ray 实现分布式调度和 shuffle。Smallpond 没有 SQL 优化器,用户需要手动编写分布式执行计划。
总结
- Python 原生,无 JVM 包袱:消除了 PySpark 的跨语言开销,对 Python 用户更友好
- Rust 执行引擎:Apache Arrow 内存模型、SIMD 向量化、高性能异步 IO
- 单机无缝衔接分布式:单机引擎 Swordfish 与基于 Ray 的分布式引擎 Flotilla 无缝切换
- 多模态原生支持:重视 AI 和多模场景,将图片、音频、向量等类型作为一等公民