A Technical Comparison of Streaming Systems

Introduction: The wave of big data has been booming for more than a decade, yet the field of stream processing seems to have been lukewarm. Until the last two years, from Confluent (the company behind Kafka) going public, to Snowflake and Databricks investing in Streaming, to the emergence of start-up companies like Decodable and Immerok. This year 2023, the SIGMOD Systems Award was surprisingly given to Apache Flink, which is somewhat exciting - has the good era of stream computing finally arrived?
Today let’s discuss stream computing (Streaming) technology from a technical point of view. Although there are many common concepts, such as time windows, watermarks, etc., in reality, each system has almost unique designs at the implementation level. The so-called “existence is reasonable”, this diversity of system design also responds to the diversity of streaming computing application scenarios, rather than simply who is better or worse on one single dimension.
This article goes deep into comparing common stream computing systems in the market, including Apache Flink, RisingWave, Spark Streaming, ksqlDB, etc. I hope that this article can help you in technology selection.
Apache Flink
Flink proposed the concept of “stream-batch integration” at the beginning, that is, to use the same Runtime to solve stream computing and batch processing. Specifically, it treats batch processing as a special case of stream processing, the difference between them is nothing more than bounded and unbounded data streams. Now it seems that although the idea of stream-batch integration has not yet deeply rooted in people’s hearts, Flink has indeed become the most popular open-source stream computing framework with its excellent design.
Like many big data frameworks, Flink computation runs on top of JVM. Flink’s programming interface is called DataStream API, and correspondingly, there is a DataStream API batch processing interface called DataSet API. On top of these two programming interfaces, they also provide a Table API and Flink SQL that are convenient for handling relational data. The above interfaces share the implementation of underlying Runtime, scheduling, data transmission layer, etc.
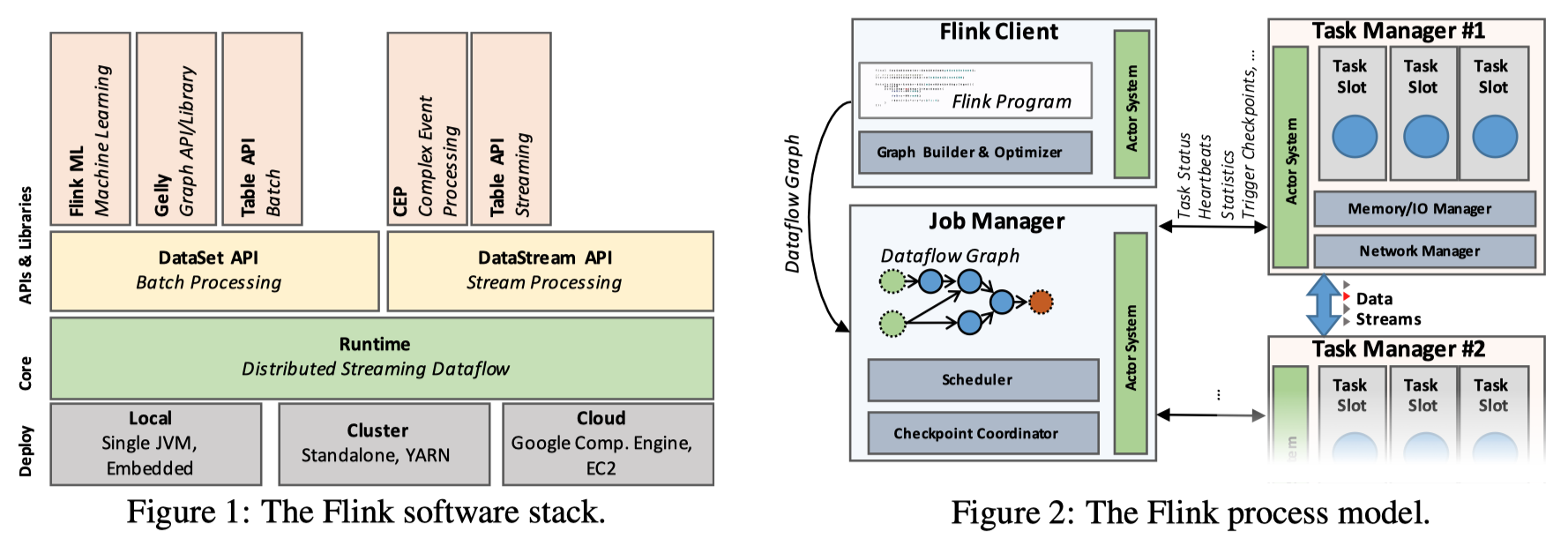
The Runtime part is basically the same as the common MPP system: operators are organized in a DAG way, and data is exchanged through local and network channels for parallel processing in shards. Many systems below are similar, and we will not repeat them for these common points.
Different from many batch processing systems equipped with columnar structure, the representation in Flink’s memory is row structure, that is, each event (or message) is used as a unit for computation and serialization when transmitting. To accelerate execution, Flink SQL uses codegen technology to generate and compile operator code in real time, making each row of computation as efficient as possible. The DataStream API can only rely on JVM’s own JIT to optimize user code.
State Management
Flink is the first stream computing system to introduce the state, and it regards stateful operators as first-class citizens. Today we are very clear that common operators such as Join and aggregation in Streaming all require state. State management is an indispensable part of Streaming, which directly determines the design of fault recovery, consistency semantics, and so on.
Flink operator states are stored in the local RocksDB instance of the operator (this is a discussion of the implementation of the open-source version of Flink). The LSM-Tree structure of RocksDB makes it easy to get an incremental snapshot, which is because most of the SST files in the current version overlap with the previous version, so only the changed part needs to be copied when copying the latest snapshot. Flink uses this feature to checkpoint the local state, and finally saves the global checkpoint on persistent storage (such as HDFS or S3).
The key to correctly performing checkpoint is how to get a globally consistent checkpoint. In this regard, Flink uses the Chandy-Lamport algorithm, which I think is Flink’s biggest design highlight. Specifically, we inject some special messages from the source of the data flow, called Barriers. Barriers will flow through the entire DAG along with other messages in the data flow, and trigger the checkpoint operation of the corresponding operator every time they pass a stateful operator. And when the Barrier flows through the entire DAG, all these checkouts compose a consistent global checkpoint.
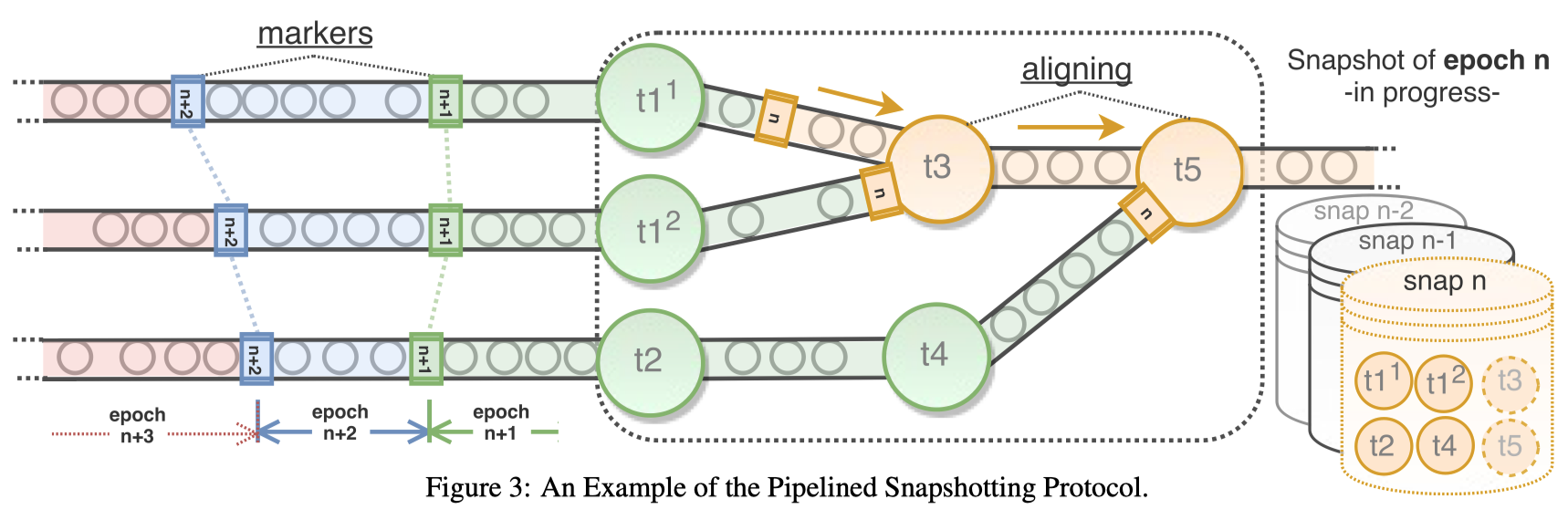
Barrier will be aligned when encountering multiple input or multiple output operators, which is the key to its guarantee of global consistency, and also the only overhead it introduces. Considering that even without Barrier, most stream computing tasks cannot avoid alignment (for example, window calculation), this cost is not high. In general, Flink has solved the consistency checkpoint in a relatively graceful way.
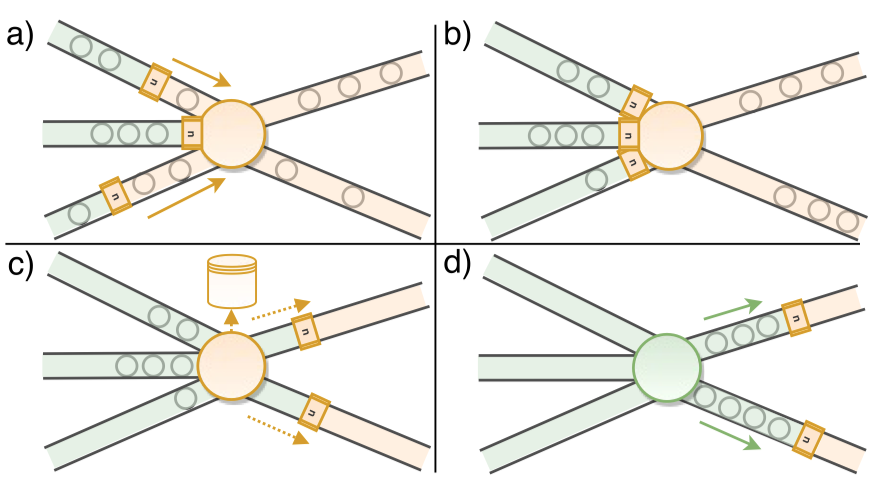
Based on the above checkpoint mechanism, at-least once and exactly-once delivery are easy to implement. For example, for replayable source (such as Kafka) and idempotent sink (such as Redis), the only thing that needs to be done is to record the current consumption offset of Kafka as part of the state in the checkpoint, which can easily achieve exactly-once delivery. For some more complicated situations, some Sinks also allow exactly-once to be implemented in cooperation with external systems through two-phase commit (2PC).
RisingWave
RisingWave is a young open-source stream computing product, which is also the project I am currently developing. It positions itself as a streaming database rather than a general stream computing framework, allowing users to define stream computing tasks in the form of materialized views using SQL. Its design goal is to make stream computing as simple as possible. It does not provide a programming API, and if necessary, users can introduce custom code logic through UDF.
RisingWave is written in Rust. In addition to the well-known advantages in memory and concurrency safety, Rust’s built-in async support and rich third-party libraries have also greatly helped us to efficiently deal with IO-intensive scenarios like stream computing. RisingWave’s stream computing task is composed of many independent Actors, which can be regarded as a coroutine, which is efficiently scheduled by user-state Runtime (tokio). At the same time, this also allows the internal implementation of the operator to use efficient single-thread memory data structures, such as the hash table used by Hash Join.
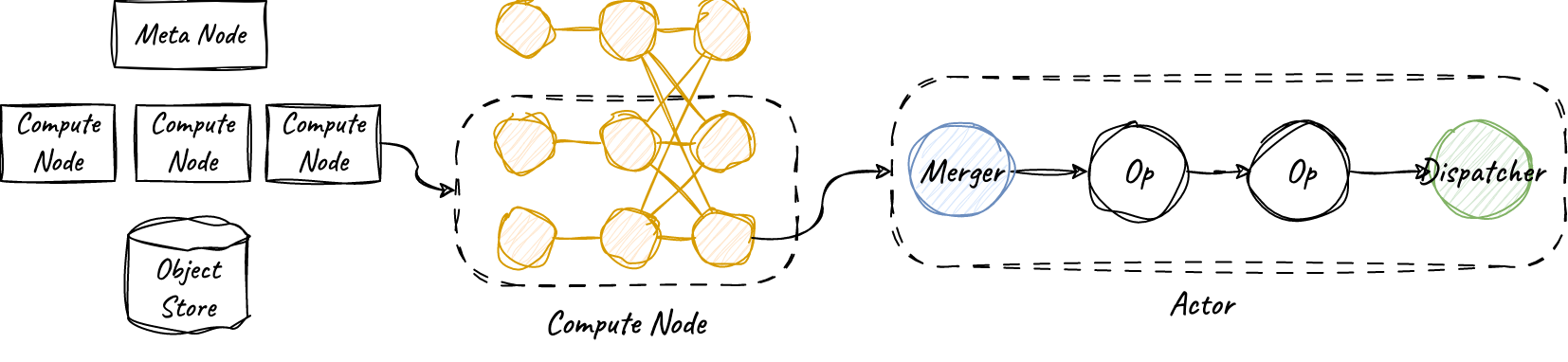
In addition to stream computing, RisingWave can also directly provide query capabilities like a database, and provide correctness guarantee for snapshot read. Specifically, as long as it is in a transaction, direct query of the results of materialized view will definitely be consistent with the results of executing its definition SQL. This greatly simplifies the verification of the correctness of Streaming tasks.
State Management
The above read consistency guarantee is inseparable from its internal checkpoint mechanism. RisingWave uses a globally consistent checkpoint mechanism based on Barrier similar to Flink, but the frequency is much higher, defaulting to once every 1s (Flink defaults to 30min). User read requests act on these checkpoints, so they always get consistent results.
In terms of storage, RisingWave did not directly use open-source components such as RocksDB, but built a storage engine based on LSM-Tree and shared storage from scratch. There are many reasons for this, the most important of them is to allow computing nodes to scale out/in more lightly, without having to copy the state files of RocksDB to new nodes like Flink. At the same time, we also hope to take advantage of the benefits of cloud object storage, such as the low cost and high reliability of S3. RisingWave built-in storage engine, and based on this implemented the ability to serve like a database query, which is a big difference from other systems.
It needs to be explained that Flink later introduced the Table Store (Paimon) storage to remedy Flink’s regret that it does not have a built-in table storage, but the main storage of the Table Store is a columnar structure, which is more suitable for analytical queries. While RisingWave’s storage engine is row-based, it is more suitable for OLTP queries such as point lookup.
Spark Streaming
Apache Spark was originally designed as a batch processing engine. Thanks to the design of RDD, Spark has better performance than Hadoop MapReduce. Interested readers can read my previous article 《Understanding Apache Spark in One Article》.
Spark Streaming uses a technology called D-Stream (Discretized Streams). Different from other streaming computing frameworks that will run operator instances for a long time, Spark Streaming divides stream data into batch processing tasks (micro-batches), and implements stream processing with a series of brief, stateless, deterministic batch processing.
Spark 2.x also introduced a new Continuous Processing Mode, but it doesn’t seem popular, so we won’t discuss it here.
The two pictures below describe how Spark implements micro-batch stream computing through RDD. For stateless computations (such as map), it’s actually no different from batch computation. For stateful computations (such as aggregation), state transitions can be regarded as iterations of RDDs, just like the counts RDD on the far right side of the right-hand picture, its ancestor (lineage) not only includes the upstream of computation, but also its previous version of RDD.
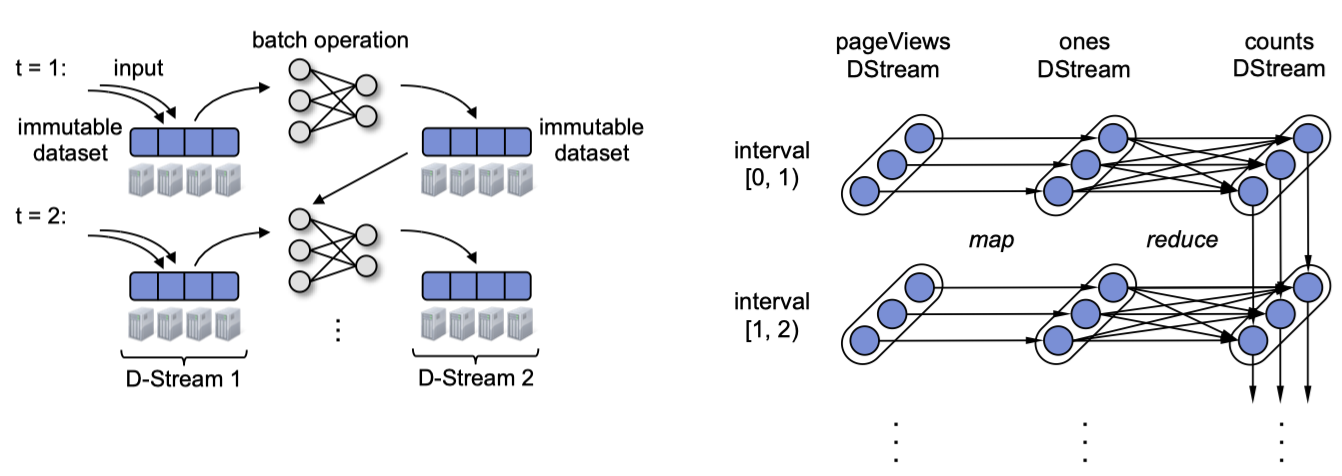
Spark Streaming cleverly converts stream computing into RDD-based batch processing, and also naturally reuses the error tolerance mechanism of RDD: just recalculate the lost RDD Partition on the failed node. However, it is obvious that there is a problem here that the ancestors of the D-Stream RDD will become longer and longer, resulting in higher and higher recovery costs, not to mention that replayable sources usually have retention restrictions. Spark Streaming periodically calls the checkpoint() function of D-Stream RDD to persist it, in order to truncate the ancestor chain.
Experience has proven that the above micro-batch scheme can achieve second to minute latency. The author of Streaming Systems also admits that in most cases, such a delay can meet the demand, which is “at most a minor complaint”. But it has to be admitted that D-Stream is just a crude imitation of stateful operators, while maintaining a simple design, it also needs to pay a higher price to achieve the same computing performance.
Google Dataflow (WindMill)
Google Dataflow, or its open-source version Apache Beam, is actually just a unified programming interface, supporting a variety of different back-end Runtimes, including Apache Flink, Spark, etc. Here we only explore Google’s own WindMill engine. Its more familiar name is MillWheel, and my understanding of it mainly comes from the VLDB'13 paper [7].
The computation and state management of MillWheel are completely decoupled. The operators written by the user read and write the persistent state saved in the Key-Value model through the State API (the above paper is BigTable). MillWheel does not have a global checkpoint mechanism. Each operator needs to write the state into persistent storage before emitting the data to the downstream, similar to the WAL of the database. The advantage of this is that the operator itself maintains the good characteristics of being stateless, which can be very convenient for fault recovery, scheduling, etc., but the cost is high, all state reads and writes need to be completed through RPC.
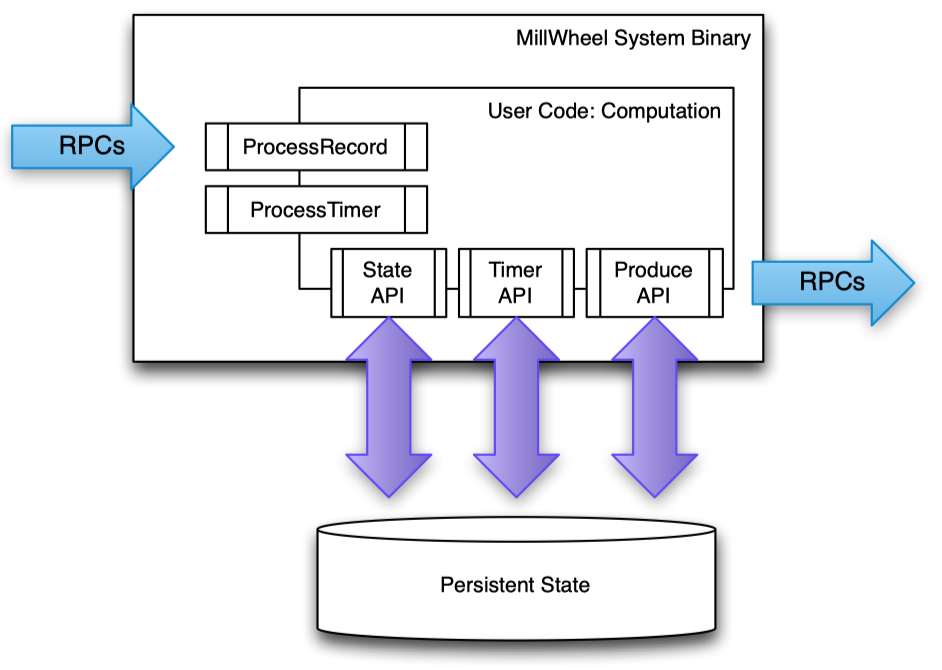
The lack of a globally consistent checkpoint also brings challenges to the implementation of exactly-once delivery. Unless the operator logic is idempotent, the operator needs to deduplicate the input to prevent duplicate messages from being processed multiple times during crash recovery, and for this, it needs to save the message log for a period of time on external storage. In general, this scheme consumes a lot of unnecessary RPC costs.
Apache Kafka (ksqlDB)
Kafka is undoubtedly the biggest player in the Streaming market. It first introduced durability into the middleware field, laying the foundation for the entire stream computing, especially exactly-once delivery. However, the reason for discussing it here is because its main role is still as a Message Broker, and it is poor in terms of computing.
ksqlDB (formerly known as KSQL) is a stream processing engine built on Kafka and developed by Confluent. ksqlDB enhances the concept of stream-table duality and introduces concepts such as materialized views, allowing users to define stream computing tasks through SQL. Although it looks very good, ksqlDB has many limitations and compromises in its design. This may be related to its positioning as a lightweight plugin, but it also forces many user scenarios to seek other solutions.
The way ksqlDB handles states is an example of these compromises. ksqlDB uses Kafka topics to save the state’s changelog and uses RocksDB to materialize these changelogs into tables for efficient querying by operators (look! A practice of stream-table duality). This roundabout method means ksqlDB consumes several times the resources for the same amount of state, and it can accidentally cause this data inconsistency bug.
Moreover, because ksqlDB tasks always run on a single Kafka node (it does not support shuffles like MPP), both aggregation and joins require the user to ensure the data has been correctly partitioned. If necessary, additional repartition topics need to be created. This also limits ksqlDB’s ability to handle complex SQL.
Others
The following systems are mostly no longer popular, but their design ideas and trade-offs still deserve our learning.
Flume/FlumeJava was originally developed by Google and is probably the earliest known stream computing system, born in 2007. It was first positioned as a programming framework convenient for developing stream computing and was later used to implement MillWheel. Its core is a data model called PCollection, an immutable, ordered, repeatable data collection, similar to Spark’s RDD. PTransform defines how to transform PCollection. Flume does not have built-in state management; users need to implement it with external databases.
Apache Storm was open-sourced by Twitter. It’s an early stream processing system, and its core data model is Tuple, similar to PCollection. Compared to other systems’ efforts on exactly-once delivery, Storm chose to pursue faster performance and give up consistency guarantees. It only supports at-least-once semantics, which makes its implementation relatively simple and efficient. As expected, Storm does not have built-in state management, users have to implement it with external databases.
Materialize may be the earliest product to propose the concept of a Streaming Database. Similar to RisingWave, it only provides a SQL interface and allows users to define tables and materialized views. Developed on the Rust stream computing framework, Differential Dataflow, it supports transformations of collections to define data streams. Operator states are stored in the in-memory Arrangement structure, and it became an essentially single-node memory database, limiting the amount of data it can handle. It also lacks a checkpoint feature and has to recover state through replay.
Summary
| Apache Flink | RisingWave | Spark Streaming | Google Dataflow | Kafka (ksqlDB) | |
|---|---|---|---|---|---|
| User Interface | DataStream API + SQL | SQL | DataStream API | Beam API | SQL |
| Data Model | Object / Table | Table | Object / Table | Object | Kafka Message |
| Consistency Guarantee | exactly & at-least once | exactly & at-least once | exactly & at-least once | exactly & at-least once | exactly & at-least once |
| State Implementation | RocksDB | In-Memory Data Structures (Cache) + Object Store | RDD (D-Stream) | BigTable | RocksDB |
| Checkpoint Storage | HDFS | Object Store | HDFS | BigTable | Kafka Topics (changelog) |
| Checkpoint Mechanism | Chandy-Lamport | Chandy-Lamport | RDD checkpoint | - | - |
References
- State management in Apache Flink: consistent stateful distributed stream processing
- Apache flink: Stream and batch processing in a single engine
- GitHub - risingwavelabs/risingwave
- Discretized streams: Fault-tolerant streaming computation at scale
- Structured streaming: A declarative api for real-time applications in apache spark
- Dataflow Under the Hood: Understanding Dataflow techniques - Sam McVeety, Ryan Lippert
- Millwheel: Fault-tolerant stream processing at internet scale.
- ksqlDB Performance Guidelines - ksqlDB Documentation
- Streaming Systems - Reuven Lax, Slava Chernyak, and Tyler Akidau
- FlumeJava: Easy, Efficient Data-Parallel Pipelines
- GitHub - MaterializeInc/materialize