LanceDB: 二进制数据湖的崛起
![]()
数据湖曾承诺可以存储任意格式的数据,但一直未能兑现——直到 AI 大模型时代对海量图像、视频、文本的需求涌现。本文以 LanceDB 为例,探讨如何通过列式存储、向量索引等技术,构建一套的二进制数据湖系统。
背景:一个迟到十年的 Use Case
2010 年前后,数据湖(Data Lake)概念横空出世。它的核心卖点之一就是:不像数仓只能存结构化数据,数据湖可以原样存储任意格式——包括图片、视频、音频。

然而事实上,这不过是一句空话。数据湖的主流用户是数据分析师和数据工程师,他们的世界里只有 CSV、JSON、Parquet。图片和视频成了 PPT 中的一句空谈。御三家 Iceberg、Delta Lake、Hudi 以及 Spark、Hive 等查询引擎都专注于结构化数据,本质上仍是在取代数据仓库的位置。
直到 AI 大模型的席卷而来。训练 GPT、Stable Diffusion 这样的模型,需要海量的图片、视频、音频、文本作为训练数据。经典做法是将每个文件单独存成 S3 上的一个 object,然后在数据库或 Parquet 里维护一张元数据表,通过文件路径去关联。但是,是否有专用的、更革命性的方式呢?
数据湖宣传了十年的那个 use case,终于真的来了,可是它却没有准备好。
解决方案:以 LanceDB 为例
设想一下,你要为这些新场景开发下一代二进制数据湖,要解决哪些核心问题?LanceDB 是当今最具代表性的二进制数据湖,它底层是 Lance 的列式存储格式(用 Rust 实现),专门针对多模态场景设计。下面我们以它为例,逐一分析这些挑战与解决方案。

存储效率
"每个文件一个 Object"的方式下,哪怕一张图片只有几十 KB,它也会在我们的元数据 DB 以及 S3 上产生一条元数据记录,独占一次 HTTP 请求。当你有 10 亿张图片时,元数据开销和 API 调用成本将变得不可忽视。理想的做法是将大量小文件合并打包成少数几个大文件,并在文件内部建立高效的随机访问索引——既降低 IO 次数,又减少 metadata 开销。
Lance 对此给出的方案是:将二进制 Blob 数据(图片、视频、音频字节)与结构化元数据(标签、时间戳、embedding 向量)存储在同一张表里,并且允许直接用 offset+size 的方式读取。相比于经典方案,这样也不再需要维护元数据和对象存储这两套系统之间的一致性。
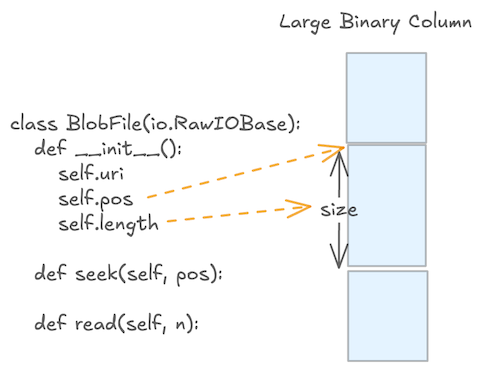
对于大型二进制字段,Lance 推荐将 Blob 数据存储在独立的文件中(称为 Packed External Blobs),而 Parquet 列只保存指向它的偏移量。读取时可以 lazy,只有当 reader 确实需要文件内容时再去发起 IO。
检索能力
把数据存起来只是第一步,能查才有价值。
按 ID 查询是最基本的需求——给定一个或一批 row ID,取出对应的图片和标注。这类点查需要 O(1) 的时间复杂度,不能全表扫描。LanceDB 的论文 对此给出了针对性的格式设计,兼顾随机访问和批处理。
Lance Format 的设计
Lance format 试图在随机访问和批处理之间取得平衡:对于大字段(向量、图片等 ≥128 字节的字段),采用"全 zip 编码"将所有 buffer 按行交错排列,使得任意行的随机读取最多只需 2 次 IOPS,与数据嵌套深度无关;对于小型数据,则使用类 Parquet 的 miniblock 分块方案。
注意这套设计的收益主要体现在 NVMe 本地缓存层(可达数十万 IOPS),在直接访问 S3 等对象存储时,由于 IOPS 上限本身就只有数万,优化空间相对有限。论文的评估也基于 NVMe 介质进行。
![LanceDB 格式对比 Parquet/Arrow 格式,来自论文 [1]](https://ericfu.me/images/lancedb-and-binary-data-lake/format-comparison.png)
二进制数据也带来了一种全新的检索范式:语义检索,比如“找出所有与这张图片语义相似的图片”。估计你已经猜到了,这是通过近似向量搜索(ANN)完成的。Lance 格式内置了向量索引。
Lance 的向量索引是一个全局索引(i.e. 不按 Fragment 分区),它分为3个独立层:
- 聚类 Clustering:通过全局 K-means 选出中心点,可以看作是向量索引自己的“分区”
- 子索引 Sub-index: 分区后的向量如何索引,可选 Flat(平铺,不索引)或者 HNSW 索引
- 量化层:可选通过量化算法压缩长度、加速计算,可选 PQ/SQ/RabitQ 等量化算法
写入时,也采用了类似 LSM-Tree 的增量 compaction 方案。详细设计可以看 Claude 老师的总结。
最后,LanceDB 将多种检索范式统一在一个查询接口里,允许混合查询:
1 | results = ( |
生态集成
最后一个问题往往被低估:数据存好了,怎么使用?
数据科学家和 ML 工程师的主要工具链是 Python。他们习惯用 Pandas DataFrame 操作数据,用 PyTorch DataLoader 加载训练数据,用 Ray Data 做分布式数据预处理。
如果只提供 SQL 接口和 Java SDK,工程师需要自己写胶水代码才能接进 PyTorch,那用户体验将是灾难性的。一套好用的 Python API 以及与 PyTorch、Ray 等软件的原生集成,是二进制数据湖的必选项。
这里还藏着一个容易被忽视的难题:现有的 Python 乃至非 Python
生态库,在设计时压根不知道什么是"数据湖"——它们统统假设数据以普通文件的形式存在于文件系统中。无论是
OpenCV 读图片、av 解码视频,还是 HuggingFace 的
Dataset,它们的 API 接受的都是一个 File
(文件描述符)或文件路径。把 blob
数据从列式存储里读出来之后,如何让它看起来像一个文件,是这条路上绕不过去的兼容性挑战。
为了对接大量假设“数据就是文件”的既有库,Lance 提供了 BlobFile
对象——一个实现了 Python io.RawIOBase 接口的
Wrapper,可以懒加载列式存储中的 blob 数据,让下游库(如
av、OpenCV)误以为自己在读普通文件:
1 | ds = lance.dataset("./videos.lance") |
当然,BlobFile 仅仅是 hack——通过实现
read()、seek()、tell()
等方法来"伪装"成文件,而非真正的文件系统路径。一旦某个库在内部绕过标准接口(比如直接传文件路径给
C 扩展、调用 os.fstat()、或使用
mmap),这层包装就会失效。
更进一步,每个框架还有自己更高层的封装。举例来说,Lance 官方为了支持 PyTorch,提供了原生的 PyTorch DataLoader:
1 | # 直接作为 PyTorch DataLoader 使用 |
换句话说,只有经过官方验证过的框架和库才能放心使用。在 AI
领域框架更新迭代极快的今天,追着各种新框架逐一适配,可能是一件耗时费力的持续性工程投入。Paimon
的 blob-as-descriptor
方案也面临同样的困境。
传统数据湖的跟进
JVM 生态的传统数据湖格式也开始意识到多模态数据的重要性,不过各家的进展和侧重点差异显著。
Apache Paimon:最积极的跟进者
Apache Paimon 是阿里巴巴主导的流批一体数据湖格式,2024 年正式从 Apache 孵化器毕业成为顶级项目。在目前几个主流格式里,Paimon 在二进制数据存储方面的工程投入是最为系统的。
Paimon 引入了专门的 Blob 存储机制 PIP-35: Introduce Blob to store multimodal data,核心设计思路与 LanceDB 有几分相似:
- 独立 Blob 文件:Blob 列不再嵌入 Parquet 文件,而是存储在独立的 blob 文件中,Parquet 只保存偏移量引用。
- 新 BlobType:在 Java API 中引入
BlobType,Flink/Spark SQL 中通过blob-fieldoption 声明,支持延迟流式读取。 - 解耦 Compaction:blob 列的 compaction 策略与结构化列分离,互不影响。
此外,Paimon 还引入了 Object Table,把对象存储中的非结构化数据(图片、视频目录)直接映射为 Paimon 表,方便用户用熟悉的 API 进行操作。
Apache Iceberg / Delta Lake:暂无动作
Iceberg v3(2025 年)和 Delta Lake 4.0(2025 年 9 月)不约而同地引入了跨生态统一的 Variant 类型,解决了半结构化 JSON 数据的存储问题,这是两个项目在"半结构化"方向最大的动作。
然而对于非结构化数据(图片、视频字节),两者目前仍然建议:不在格式内处理,建议将文件存对象存储、路径引用存表。Iceberg 社区早在 2020 年就有 unstructured module 的提案,至今仍停留在概念阶段。这是 Parquet 列式 Row Group 机制的架构决定的——混入大体积 blob 极易触发 OOM,短期内难以根本性改变。
Apache Hudi:已制定 Roadmap
Hudi 1.x 路线图明确将非结构化 Blob 的原生支持(索引、更新、变更捕获)列为重点,并在引入向量索引能力,朝“AI 原生 Lakehouse”方向演进。相关进展包括:RFC-100: Unstructured Data Storage in Hudi, #14290 Add Support for Vector Indexing in Apache Hudi 等。社区贡献者也在探索将 LanceDB 集成进 Hudi 生态,用 Hudi 管理 ACID 语义、用 LanceDB 提供向量检索。不过完整的生产级实现尚未到来,目前仍是 Roadmap。
但是,你真的需要吗?
技术选型是 trade-off 的艺术。对象存储的高延迟是不可避免的,无论格式多先进都无法改变。即使是 Lance 声称的“100x 快于 Parquet 的随机访问”,其绝对延迟仍在毫秒到数十毫秒量级——与具备 buffer pool 和本地盘的数据库、数据仓库相比,仍有数量级的差距。
那么,二进制数据湖适合哪些场景呢?
- 对延迟不敏感的批处理任务,尤其是模型训练。 大模型训练的 DataLoader 可以在 GPU 计算的同时预取下一批数据,只要数据吞吐量够高,几十毫秒的单次读取延迟完全可以被流水线掩盖。
- PB 级数据量,降低存储成本成为最高优先级。 当数据规模达到 PB 级,S3 存储成本(相对于 SSD)的优势就会变得极其显著——可能相差 10 到 100 倍。此时勉强够用的延迟 + 极低的存储成本往往是最优解,没得选。
而像在线推理的实时特征获取、以及任何 P99 延迟要求在 50ms 以内的服务。这类场景应该选择向量数据库+Object等低延迟方案。