SIGMOD21 | Milvus: 向量数据库
![]()
Milvus 是一个用于向量(Vector)存储和检索的特殊数据库,由国内的创业公司 Zilliz 开发。本文内容来自 Milvus 在 SIGMOD'21 上的论文 Milvus: A Purpose-Built Vector Data Management System。
所谓向量,可以看作一个长度为 N 的元组。很多 AI/ML 系统(例如推荐系统、图片相似度检测等)都有类似的需求:这些系统首先将海量数据集经过特征提取得到很多向量,使用时给定一个向量,从数据集向量中快速检索出和它最"相似"的的 K 个向量。相似度的定义有多种,最常见的有余弦距离、欧几里得距离等。
为了做到这一点,最 naive 的方法就是让给定向量和所有数据库中的向量依次做比较,但显然这个做法太慢了。RDBMS 中有索引的概念,那我们能不能为向量的相似度也建立索引呢?当然是可以的!
这个问题称为向量相似度检索(vector similarity search),Facebook 开源的 Faiss 就是这样一个 C++ library,它内置了多种索引,例如 IVF_FLAT、IVF_FQ8、IVF_PQ 等(这些算法不是本文的重点)。Milvus 基于 Faiss 开发,Milvus 添加了存储组件,使之成为一个完整的数据库产品(而不仅是个 libaray),同时也做了很多工程上的优化。
存储格式
Milvus 的数据模型允许每行数据(文中称为 entity)包含 1 个或多个 vector 以及可选的数值属性(numeric attribute)。其中数值属性一般起到过滤作用,比如年龄、身高之类的,可以作为查询过滤条件的一部分。
每个 vector 本身显然是要连续排列的(vector 一定是以整体参与运算),而 vector 之间按列排列。比如一张表有 v1、v2 两个 vector 列、{A,B,C} 三行数据,那么在存储上的排列就是 {A.v1, B.v1, C.v1, A.v2, B.v2, C.v2} 。
数值属性的排列比较有意思,同样是先按列分开,每个列内部类似一个有序的倒排索引:属性的数值 -> Row ID,通过 RowID 就可以找到相应的 vector。这样的设计是为了支持高效的 point/range query(comment: 但同时也意味着 select 这些属性的代价变得很高,所以估计不支持 select 吧,若理解有误欢迎指正)。
存储采用类似于 LSM-Tree 的分层 compaction 设计。新写入的数据会进入
MemTable,MemTable 会刷到磁盘上,同时构建索引。和很多 OLTP
系统的不同之处是,Milvus
并不保证写后读,除非手动调用 flush() API
否则可能查不到新写入的数据(之所以这样也和后面的 shared-storage
架构有关)。但是 Milvus 可以保证读到的 Snapshot
是一致的(例如不会读到写了一半的数据),实现原理也很简单:在读取时记录下当前所有
SS-Table 的文件集合快照,从这个快照中读取。
Milvus 的分布式架构是个基于共享 object storage 的一写多读架构,有点类似于 Snowflake。writer 始终只有一个,因此也不会用到分布式事务。reader 可以横向扩展,通过 coordinator 可以将一个查询根据分片+路由的方式打到所有 reader 上,将查询在多个节点上并行起来。每个 reader 都可以利用本地的磁盘和内存缓存一些热数据。
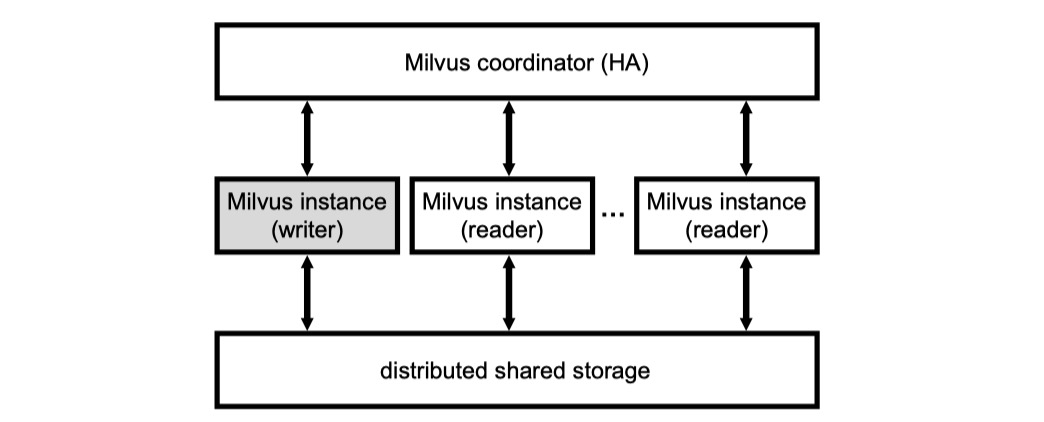
Milvus 通过 WAL 保证原子性和持久性,WAL 同样位于共享存储层上。(comment: 这样延迟可能会比较大?)
索引选择
索引的原理超出本文的 scope,这里只介绍最基本的 idea:在 build 索引时,会通过聚类算法选出几个中心点(v0~v9 聚类得到图中 c0~c2 三个中心点),当给定查询 q 时,算法能快速找到离 q 最近的 k 个中心点(k=2,得到 c0、c1),之后只要从 c0、c1 的邻居中(v0~v6)搜索即可。
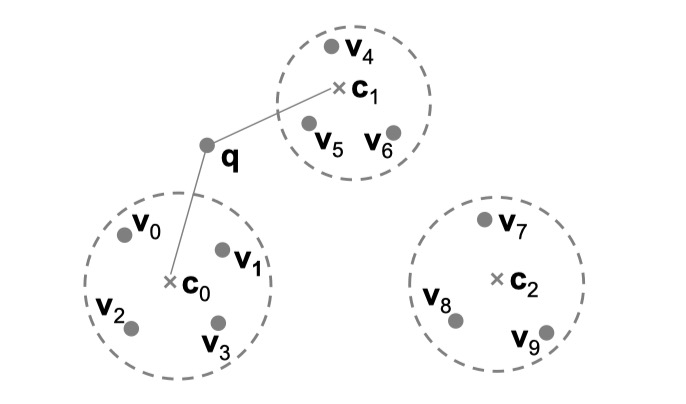
显然,索引是一个和数据相关的 immutable 的数据结构,这一点和 LSMTree 的结构天然契合:从 MemTable 写到磁盘的时候或者 compaction 的时候 build 索引即可。
索引选择的实现是基于 cost 的:
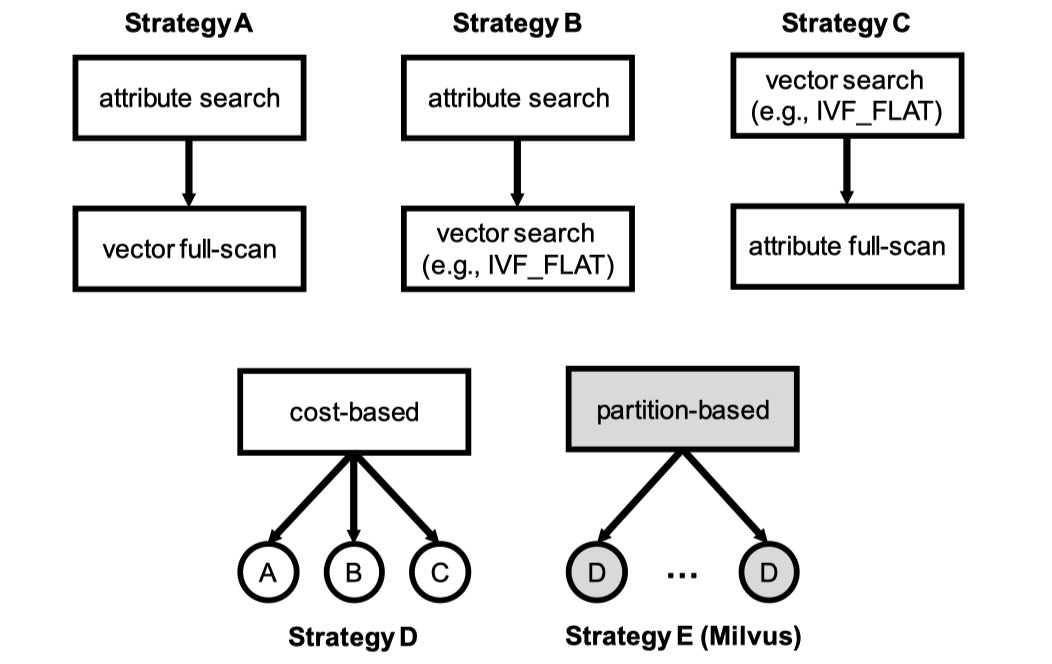
策略A(vector不走索引,数值条件走索引):先通过数值属性的倒排索引过滤,再在过滤出来的所有数据上扫描(逐个计算相似度,不依靠vector的索引)
策略B(vector走索引,数值条件走索引):通过数值属性的倒排索引拿到过滤结果 bitmap,然后在 vector 上利用相似度索引得所有相似的向量,根据 bitmap 只留下复合过滤条件的那些,再取 TopK
策略C(vector走索引,数值条件不走索引):在 vector 上利用相似度索引得所有相似的向量,然后按数值条件过滤
策略D:基于代价在 A/B/C 中选择一个,至于怎么选应该很容易想到吧 :)
策略E:是对 D 的进一步改进,也是 Milvus 使用的策略。具体来说,Milvus 首先根据某个数值属性将整个 dataset 分区(比如 price 可以分为 [1, 100], [101, 200], [201, 300], [301, 400] ),之后,如果查询条件带有分区键,则可以进行"分区裁剪"(比如对于 price in [50, 250],可以直接裁剪出 [1, 100], [101, 200], [201, 300] 这三个分区),并且对每个分区采取 cost-based 策略(比如中间的 [101, 200] 区间不需要对 price 进行过滤,因为一定满足条件)
工程优化
- 对 Faiss 的 cache-miss 问题做了优化,性能提升 1.5x ~ 2.7x- 支持 SIMD,支持根据 cpu 指令集选择最高效的 SIMD 指令集(SSE/AVX/AVX2/AVX512)- 更好的 GPU 支持:允许更大的 Top k,允许多 GPU- GPU & CPU 混合计算
优化效果可以参见原文 Evaluation 一节,这里不贴了。
补充:据说论文的架构是Milvus 1.x的架构,2.0新架构大幅重构了,见文档 Milvus Architecture Overview - Milvus documentation