Calcite 对 Volcano 优化器优先队列的实现
Apache Calcite 中的 VolcanoPlanner 是对 Volcano/Cascades 优化器的实现。我们知道,Volcano 优化器是在搜索空间中用动态规划(DP)的方式寻找最优解,即使在用了 DP 的情况下,我们也不大可能把搜索空间遍历完。Volcano 的解决方案是定义一个优先队列,优先采用看起来更有希望的 Rule。
于是问题来了,怎样定义一个 Rule 的优先级?论文中并没有给出答案。Calcite 代码中为此定义了 Importance 的概念。然而相关的资料非常少,本文总结一下我自己的猜测和理解,如果你有不同的观点,欢迎留言讨论。
术语
本文假设读者已经充分理解 Volcano 优化器。对以下概念有疑问的,请参考 Valcano/Cascades 原论文。
- RelSet 描述一组逻辑上相等的 Relation Expression
- RelSubset 描述一组物理上相等的 Relation Expression,即具有相同的 Physical Properties
- RuleMatch 描述一次成功的匹配,包含 Rule 和被匹配的节点
- Importance 描述 RuleMatch 的重要程度,越大越应该优先处理
基本原则
为了能在短时间内得到一个较优解,我们的基本原则是:尽量对代价大的做优化,从而尽可能在有限的优化次数内获得更大的收益。这又可以分成三个方面来说:
- 优先应用 Transformation Rules 生成各式各样的关系表达式(即优先进行 explore 过程);
- 一般来说,父节点比子节点数据量更大,所以优先处理父节点;
- 同级的节点中,代价大的一边应该得到更多的优化。
为了达成 1,我们只要把逻辑算子的代价设为无穷大即可。为了达成 2、3,我们将 importance 和 cost 关联起来——简单来说就是 cost 越大、importance 也越大。
实现分析
原理上说,RuleQueue 是一个优先队列,包含当前所有可行的
RuleMatch,findBestExpr()
时每次循环中我们从中取出优先级最高的并 apply,再根据 apply
的结果更新队列……如此往复,直到满足终止条件。
但因为性能原因,实际上 RuleQueue 没有使用最大堆之类的数据结构,而是每次选出 importance 最大的那个。这是因为经常需要对 RelSubset 的 importance 做大量调整,用最大堆处理得不偿失。
RuleMatch 的 importance 定义为以下两个中比较大的一个:
- 输入的 RelSubset 的 importance
- 输出的 RelSubset 的 importance
以上参考
VolcanoRuleMatch:computeImportance
那 RelSubset 的 importance 如何决定?这边的实现比较 tricky:RuleQueue
的成员变量 subsetImportances 中保存了各个 RelSubset 的
importance,但这并不是 getImportance()
返回的结果。为了区分清楚,我们把 getImportance()
返回的结果称为调整后的 importance,把 subsetImportances
里存的值称为真实 importance。
调整后的 importance 定义为以下两个中比较大的一个:
- 该 RelSubset 本身的真实 importance
- 逻辑上相等的(即位于同一个 RelSet 中)任意一个 RelSubset 的真实 importance 除以 2
之所以要这么做,注释中的解释是让 Conversion 尽快发生。
以上参考
RuleQueue:getImportance(RelSubset)
下一个问题,真实 importance 怎么计算呢?
- 根节点的 importance 始终是 1.0
- 否则,假设它父节点的代价是 \(c_{parent}\),这个节点本身的代价是 \(c_{child}\),则定义节点本身的 \(I_{child} =\frac{c_{child}}{c_{parent}} I_{parent}\)
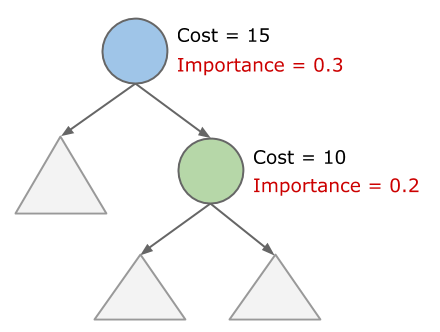
这里说的 cost 是 RelSubset 的 cost,也就是当前这个 RelSubset 的中最佳 Physical Plan 的 cost。DP 算法会保留每个 RelSubset 的最佳 plan 以及对应 cost。
以上参考
RuleQueue:computeImportance(RelSubset)
这个定义又引出了下面两个问题:
1. 如果一个 RelSubset 里还没有 Physical Plan,那它的 cost 是无穷大,怎么处理?
初始设置为 \(0.9^n\),其中 \(n\) 是 RelSet 所在的层数(参考
VolcanoPlanner:setInitialImportance)其他时候,比例 \(\frac{c_{child}}{c_{parent}}\) 限制最大不超过 \(0.99\)(参考
RuleQueue:computeImportanceOfChild)
PS. 理论上只要是一个小于 1 的系数都可以,不知道为什么这里两个系数不一样。
2. 如果某个 RelSubset 的 cost 降低了(例如找到了一种 Physical Plan),那么 importance 也应该相应的被更新。
- 要更新的不仅是该 Plan 本身所在的一个或多个 RelSubset,还有可能是这些
RelSubset 的父节点、父节点的父节点……所以这是一个向上递归的过程。(参考
RelSubset:propagateCostImprovements)
References
- The Volcano Optimizer Generator: Extensibility and Efficient Search - Goetz Graefe
- The Cascades Framework for Query Optimization - Goetz Graefe
- Apache Calcite Source Code