到底什么是时序数据库?

在我听说过的许多数据库领域的名词中,“时序数据库”是一个严重过载的概念。即使听上去很简单,但是在许多商业产品的包装下,它的定义变得十分模棱两可。在这篇文章中,我想给“时序数据”一个清晰的定义,以帮助你理解为什么会有这样的一类数据库、它应该用于什么场景、以及如何将你的数据正确建模成时序数据。
定义时序数据模型
数据模型(data model)是个最基础却也常被忽略的概念。我们都知道,关系型数据库基于关系代数定义了关系表和各种运算,文档型数据库则是把每个数据看作一个半结构化(JSON)的对象。但很不幸,市面上的时序数据库没有完全就数据模型达成一致。
让我们从最简单的开始。时序数据(time series)是一个由「时间戳-值」对组成的序列,通常表示某一个特定东西在时间上的变化。由于变化往往是连续的,我们常常将它们用线图来可视化。
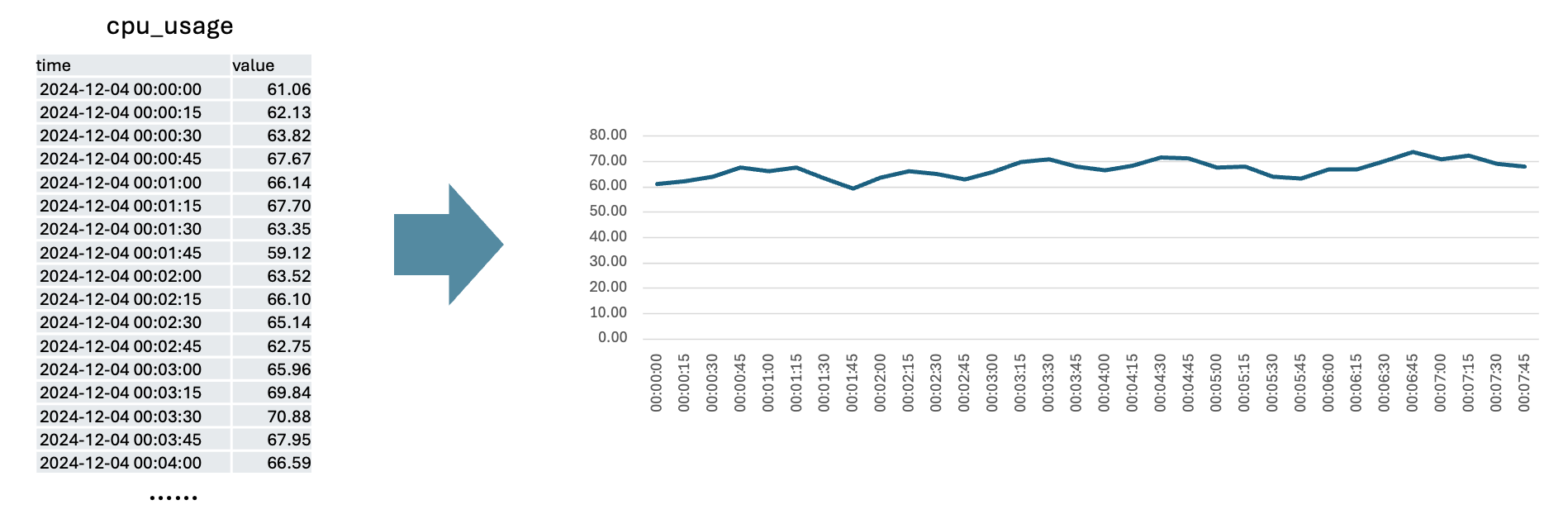
实际中,时序数据往往是成组出现的。例如,如果我们给服务器集群装监控,那么每个节点都会有一个对应的
cpu_usage time series,这些 time series
都叫同样的名字(cpu_usage),并且用标签(label 或
tag)来区分彼此,这些标签通常是 {key=value} 的形式。
| 指标名称 | Labels | Value 的含义 |
|---|---|---|
cpu_usage |
集群名、节点名 | CPU 使用率百分比 |
temperature |
Sensor ID、经纬度 | 传感器记录的当前温度 |
stock_price |
股票代码 | 某只股票的交易价格 |
到目前为止,我们已经有3个维度了:时间戳(timestamp), 指标名称(metric name 或者 table), 以及标签集合(label set),它们组合起来才能唯一确定一个数据点(value)。
\[ (time, name, labels) \rightarrow value \]
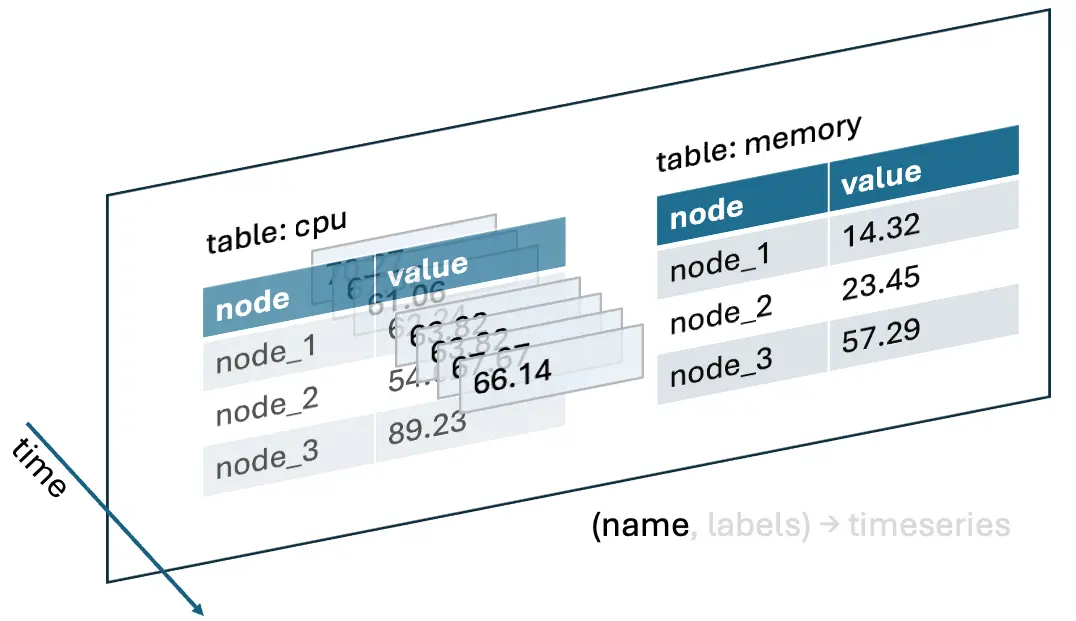
把 labels 的所有枚举平铺展开成一张表,就可以画出下面的示意图。其中,XY 方向的平面对应 name 和 labels,Z 轴对应时间。

有趣的是,你可以从两个视角来看待这个模型:
- \((name, labels) \rightarrow timeseries\):在这个视角中,你通过 name 和 labels 找到一个(或一组) time series 向量,后续的操作也都作用于当前 time series 的所有数据点。这个视角更接近于传统的关系型数据库,例如 InfluxDB 的 InfluxQL 就是基于这个视角设计的。
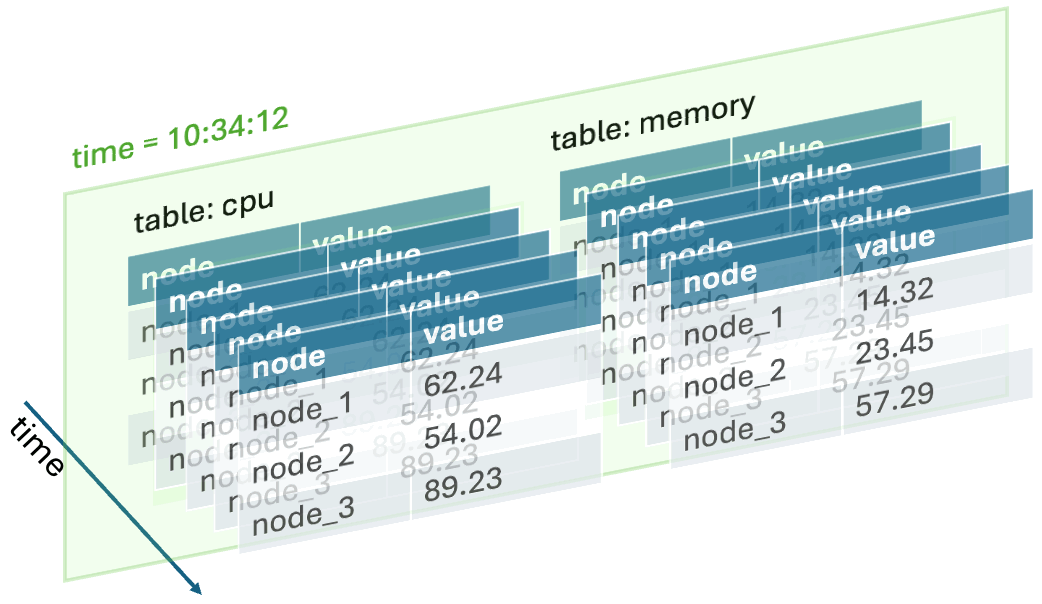
- \((time) \rightarrow (table, labels, value)\),在这个视角中,你先选定一个特定时间点的切片(snapshot),这个切片上面的 value 对应于所有 time series 在这个时间点的值。查询语言只需描述对单个时间切片的数据应该如何处理,因为每个切面都会重复完全一样的计算。Prometheus 的 PromQL 就是这样设计的。1
时序数据的计算
有了这个数据模型,我们就可以基于它定义计算和查询。相比于关系模型的「二维表」,时序数据是一组「三维表」,多出的维度即是时间。我们稍后会看到时间维度带来的特殊性。
标量运算
标量(scalar value)其实就是对单个值的计算,例如
cpu_usage * 100将 cpu_usage 数值从小数转换为百分比net_read + net_write将网络读、写速率相加cpu_usage > 80将大于 80%的 CPU 使用率标记为 true2
标量计算是最基础的计算,你可以试着用视角1和视角2分别理解一下它们,当然,一定会导出相同的结果。
聚合
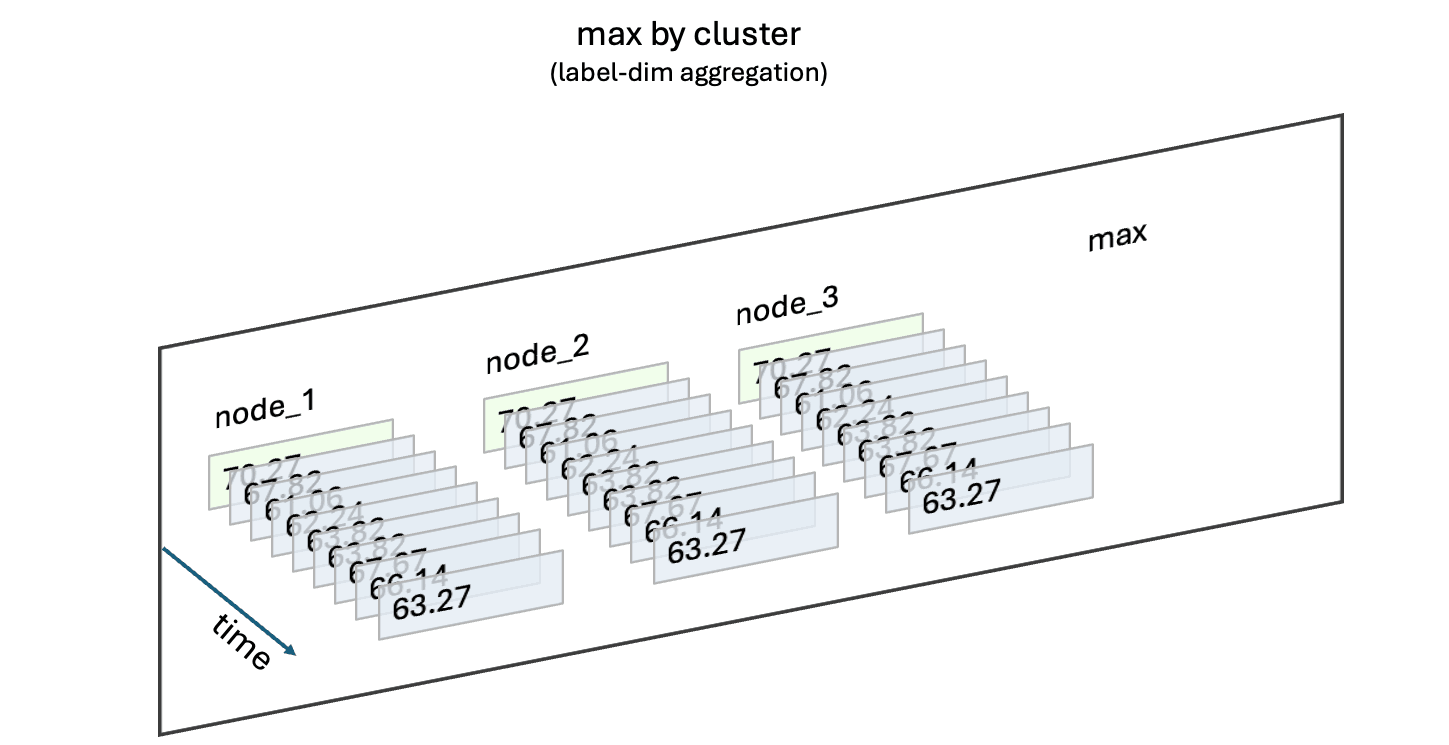
时序数据库的聚合可以分为两类:
- 时间维度的聚合,亦是应用在每一条 timeseries 上的操作,典型的有分桶聚合、求导(增长率)、线性回归等,例如:每5分钟窗口的最大CPU使用率
- 标签维度的聚合,亦是应用在每一个时间切片上的操作,典型的有求和、Quantile、TopK 等等,例如:集群中各节点的最高CPU使用率
时间维度的聚合
以最常见的 downsample 为例,常常要借助时间窗口函数或者
extract()
函数对齐对特定时间,例如,按小时或按天,然后再进行聚合操作。由于聚合发生在时间维度上,因此它是对每个
time series
的操作:fn(input: timeseries) -> timeseries。
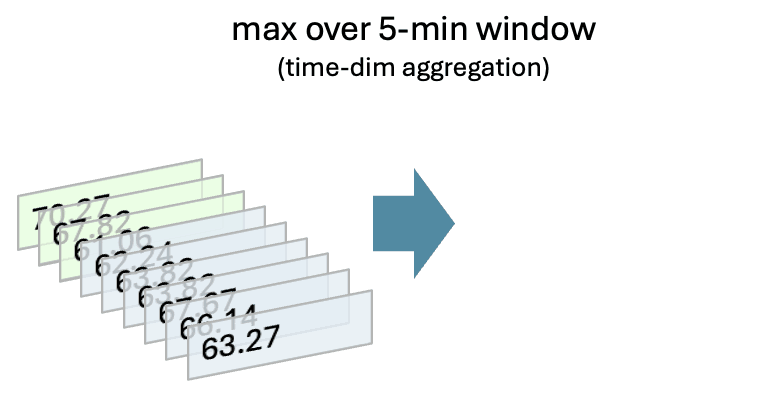
特别地,当时间维度的聚合遇到某个时间段恰好缺失数据点的时候,常常会用空值进行填充或者通过前后数据点进行线性插值(gap-filling),让数据更规整方便后续处理。而标签维度的聚合显然不存在这个问题。
标签维度的聚合
以 sum (cpu_usage) by (cluster)
为例,它可以被理解在每一个时间切片上对 cpu_usage
进行分组聚合(视角二) :
1 | for each timestamp: |
你也可以将它看作对 time series
向量整体进行的操作(视角一)。用后者实现的效率相比前者高很多,不仅因为每次
GROUP BY
的过程其实是完全一样的,还因为可以利用向量化加速计算。
由于被聚合的通常是多个 time series,可以记作
fn(inputs: List[timeseries]) -> timeseries。又由于聚合可以看作发生在每个时间切片的内部,时间维度本身(timestamp
向量)不会变化。
| 聚合类型 | 输入 | 输出 | 改变向量长度 | Gap-filling | 例子 |
|---|---|---|---|---|---|
| 时间维度 | 单个 time series | 单个 time series | 是 | 可选 | 每5分钟窗口的最大CPU使用率 |
| 标签维度 | 多个 time series | 单个 time series | 否 | 无 | 集群中各节点的最高CPU使用率 |
除了概念上的,两者的不同也体现在实现上。大多数时序数据库都有特化的 time series 向量数据结构,在文件和内存中使用列式结构连续地保存 timestamp 和 value,从而压缩空间、提升查询速度等。尽管都能受益于列式内存结构,但是时间和标签维度聚合是完全不同的算子实现,这一点光是从输入上就能看出来:前者是输入单个 time series,后者是输入多个 time series。
在一些兼容 SQL 的时序数据库中,两种聚合都用
GROUP BY表示,最后实际采用哪个实现取决于GROUP BY的字段是时间戳还是标签。
Join 操作
Join 操作通常同时发生在时间维度和标签维度上,它是将两个 time series 向量按照时间戳对齐,每个 value 也与另一个 value 相对应。注意由于采集的延迟,每个 time series 的时间戳可能并不完全对齐。
从视角2理解 Join
操作则比较容易:在某个时间切片上,像对待二维关系表那样进行 Join
操作即可。唯一剩下的问题是如何把两个 time series
对齐到同一个时间切片上,一种简单的方式按特定间隔对齐,例如将时间戳都取整到分钟;另一种常见的处理方式是
AS OF JOIN,例如 t1 AS OF JOIN t2 将 t2
的时间戳关联到最新且小于 t1
的时间戳,它表达的含义是:在 t1 发生时(“as of t1 happens”),t2
的值是多少。
案例分析
Prometheus
Prometheus 的数据模型很大程度上符合上面的定义。在 Prometheus
中,每个指标(metric)都是一个 time series,它有一个名字(metric
name)以及一组标签(labels),例如
cpu_usage{cluster="prod", node="node1"}。
Prometheus 的查询语言 PromQL 基于视角2设计,即在特定的时间切片上对
value 进行运算,例如
max(cpu_usage{cluster="prod"}),“特定时间”作为另一个参数会同
query 一起被调用。对于某些跨越多个时间的操作,例如 rate
增长率 = (最新值 - 最旧值) / 经过时间。对此,PromQL 也提供了
[] 操作符来取出从当前查询时间点往前一段时间的 time
series,例如 rate(count_requests[1m]),计算过去 1
分钟的请求吞吐量。
实际使用中,为了绘制变化曲线,往往要一次性查询一段时间范围内的数据,这时候就需要利用 Range query API, 指定开始时间、结束时间以及步长,例如
1 | $ curl 'http://localhost:9090/api/v1/query_range?query=up&start=2015-07-01T20:10:30.781Z&end=2015-07-01T20:11:00.781Z&step=15s' |
它完全等价于发出多个 Instant query 然后将结果合并成一个时间序列。
PromQL 的设计非常简洁易懂,但对于某些场景也稍显表达力不足,例如为了
max_over_time,不得不引入了难懂且低效的子查询。
InfluxDB
InfluxDB 是另一个流行的时序数据库,它的数据模型同样符合本文的定义。在 InfluxDB 中,每个 time series 都有一个名字(measurement),以及一组标签(tags)和字段(fields)。它的查询语言 InfluxQL 模仿了 SQL 语法,基于视角1或者说 data-oriented 的视角设计。
InfluxDB 的内部存储引擎 Time-Structured Merge Tree (TSM) 按照 tags 将同一个表分成多个 time series 向量,并按照时间戳排序。由于 tags 被用于标识不同的 time series,因此你也要小心保证 tags 的数量不要过多,否则会导致 time series 向量过多,影响查询性能。
GrepTime
GrepTime 是一个新兴的时序数据库,它的数据模型符合本文定义,每个 time series 都有一个名字(metric name)以及一组 tags,可以包含多个 fields。由于都是借用了关系模型,和 InfluxDB 也很相似。
GrepTime 采用了 LSM-Tree 的存储引擎,但要注意它的 SST 文件采用列式格式(Parquet),并且按照 (tag-1, ..., tag-m, timestamp) 的顺序排序,猜测这样可以在保证查询性能的同时兼顾 update 和点查的性能。
TDEngine
TDEngine 的数据模型符合本文定义,每张表都有一个名字以及一组 tags,可以包含多个 fields。由于都是借用了关系模型,和 InfluxDB 也很相似。
早期 TDEngine 出于效率考虑,建议用户为每个采集点创建一张表,但是随后发现,随着规模增大,需要不断改写查询引用更多的表。所以 TDEngine 又引入了“超级表”的概念,将一张逻辑表通过不同的 tag 分成不同子表。这和 InfluxDB TSM 的设计如出一辙。
TimescaleDB
TimescaleDB 不符合本文对时序数据库的定义,它更像是一个为冷数据特别优化过的关系型数据库。考虑到它其实是 PostgreSQL 的一个扩展,这也不奇怪。
这篇博客文章揭示了 TimescaleDB 的内部存储结构:在 Posgres 原有表结构的基础上,它将“冷却”的数据用类似于 array 的格式重新组织,牺牲更新性能换取了扫描性能和压缩比。
TimescaleDB 遵循一般的关系型数据库模型,因此你可以几乎将一切带有时间的数据都存储在 TimescaleDB 中。它的优势在于可以利用 PostgreSQL 的强大功能,例如索引、事务、外键等等。但是,由于它并没有特化的 time series 向量对象,因此处理标准的时序数据(例如 metrics)就无法发挥出太多性能优势。
QuestDB
QuestDB 同样不符合本文对时序数据库的定义,它是一个为 append-mostly workload 优化的数据库,具有极高的 ingestion 性能。它基于一个简化版的关系模型,包括 index、join 等。
QuestDB 采用最简单直接的列式存储结构:新的数据不断被 append 到最新的 chunk 中。但对于 update,就需要引入更复杂的 versioning 以及后台 Vacuum 机制,这也是为什么 QuestDB 不适合频繁更新的场景。
同样地,如果你的数据完美符合时序数据的定义,那么你应该选择专门的时序数据库。