JIT 代码生成技术(一)表达式编译
代码生成(Code Generation)技术广泛应用于现代的数据系统中。代码生成是将用户输入的表达式、查询、存储过程等现场编译成二进制代码再执行,相比解释执行的方式,运行效率要高得多。尤其是对于计算密集型查询、或频繁重复使用的计算过程,运用代码生成技术能达到数十倍的性能提升。
当我们谈论代码生成时我们在谈论什么
很多大数据产品都将代码生成技术作为卖点,然而事实上他们往往谈论的不是一件事情。比如,之前就有人提问:Spark 1.x 就已经有代码生成技术,为什么 Spark 2.0 又把代码生成吹了一番?其中的原因在于,虽然都是代码生成,但是各个产品生成代码的粒度是不同的:
- 最简单的,例如 Spark 1.4,使用代码生成技术加速表达式计算;
- Spark 2.0 支持将同一个 Stage 的多个算子组合编译成一段二进制;
- 更有甚者,支持将自定义函数、存储过程等编译成一段二进制,例如 SQL Server。
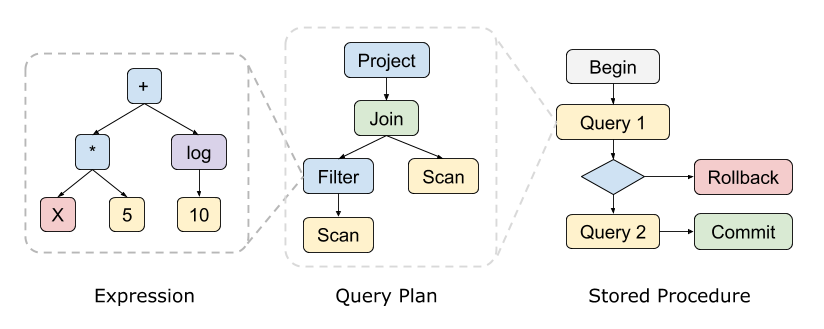
本文主要讲上面最简单的表达式编译。让我们通过一个简单的例子,初步了解代码生成的流程。
解析执行的缺陷
在讲代码生成之前,我们回顾一下解释执行。以上面图中的表达式
- 调用根节点
+的visit()函数:分别调用左、右子节点的visit()再相加; - 调用乘法节点
*的visit()函数:分别调用左、右子节点的visit()再相乘; - 调用变量节点
X的visit()函数:从环境中读取的值以及类型。
(……略)最终,DFS 回到根节点,得到最终结果。
1 | public Object visitPlus(CalculatorParser.PlusContext ctx) { |
上述过程中有几个显而易见的性能问题:
- 涉及到大量的虚函数调用、即函数绑定的过程,例如
visit()函数,虚函数调用是一个非确定性的跳转指令, CPU 无法做预测分支,从而导致打断 CPU 流水线; - 在计算之前不能确定类型,因而各个算子的实现中会出现很多动态类型判断,例如:如果
+左边是 DECIMAL 类型,而右边是 DOUBLE,需要先把左边转换成 DOUBLE 再相加; - 递归中的函数调用打断了计算过程,不仅调用本身需要额外的指令,而且函数调用传参是通过栈完成的,不能很好的利用寄存器(这一点在现代的编译器和硬件体系中已经有所缓解,但显然比不上连续的计算指令)。
代码生成基本过程
代码生成执行,顾名思义,最核心的部分是生成出我们需要的执行代码。
拜编译器所赐,我们并不需要写难懂的汇编或字节码。在 native 程序中,通常用 LLVM 的中间语言(IR)作为生成代码的语言。而 JVM 上更简单,因为 Java 编译本身很快,利用运行在 JVM 上的轻量级编译器 janino,我们可以直接生成 Java 代码。
无论是 LLVM IR 还是 Java 都是静态类型的语言,在生成的代码中再去判断类型显然不是个明智的选择。通常的做法是在编译之前就确定所有值的类型。幸运的是,表达式和 SQL 执行计划都可以事先做类型推导。
所以,综上所述,代码生成往往是个 2-pass 的过程:先做类型推导,再做真正的代码生成。第一步中,类型推导的同时其实也是在检查表达式是否合法,因此很多地方也称之为验证(Validate)。
在代码生成完成后,调用编译器编译,我们得到了所需的函数(类),调用它即可得到计算结果。如果函数包含参数,例如上面例子中的
X,每次计算可以传入不同的参数,编译一次、计算多次。
以下的代码实现都可以在 GitHub 项目 fuyufjh/calculator 找到。
验证(Validate)
为了尽可能简单,例子中仅涉及两种类型:Long 和 Double
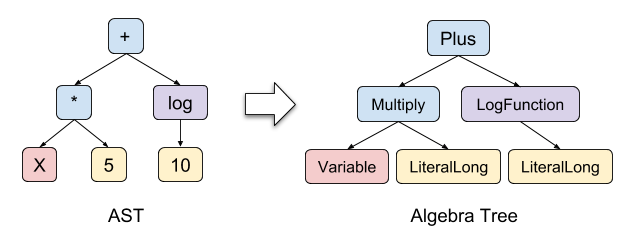
这一步中,我们将合法的表达式 AST 转换成 Algebra Node,这是一个递归语法树的过程,下面是一个例子(由于 Plus 接收 Long/Double 的任意类型组合,所以此处没有做类型检查):
1 | public AlgebraNode visitPlus(CalculatorParser.PlusContext ctx) { |
AlgebraNode 接口定义如下:
1 | public interface AlgebraNode { |
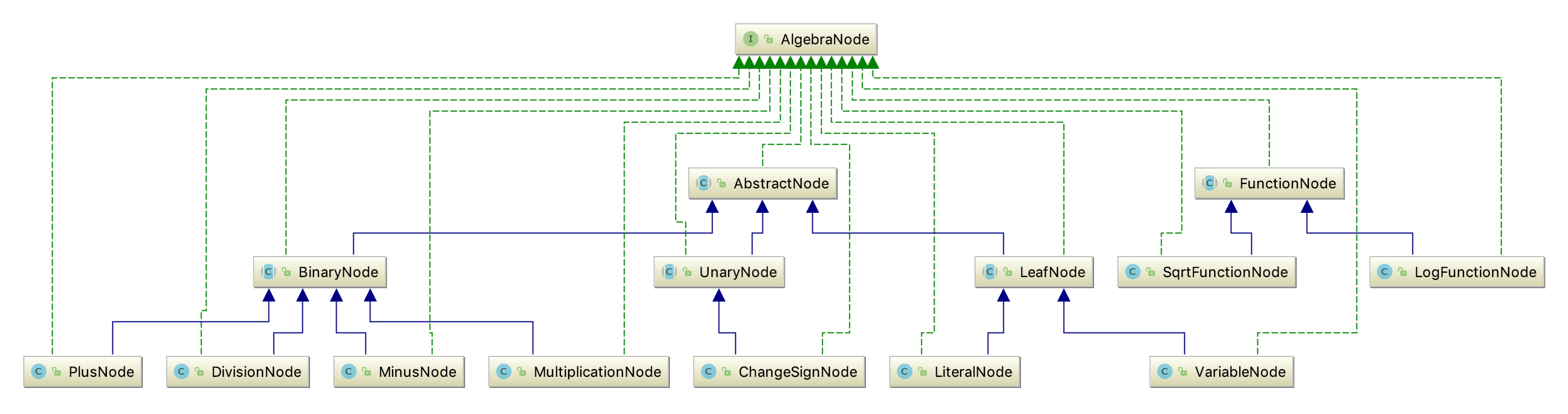
实现类大致与 AST 的中的节点相对应,如下图。
对于加法,类型推导的过程很简单——如果两个操作数都是 Long 则结果为 Long,否则为 Double。
1 | public DataType getType() { |
生成代码
依旧以加法为例,利用上面实现的
getType(),我们可以确定输入、输出的类型,生成出强类型的代码:
1 | public String generateCode() { |
注意,目前代码还是以 String 形式存在的,递归调用的过程中通过字符串拼接,一步步拼成完整的表达式函数。
以表达式 a + 2*3 - 2/x + log(x+1)
为例,最终生成的代码如下:
1 | (((double)(a + (2 * 3)) - ((double)2 / x)) + java.lang.Math.log((x + (double)1))) |
其中,a、x
都是未知数,但类型是已经确定的,分别是 Long 型和 Double 型。
编译器编译
Janino
是一个流行的轻量级 Java 编译器,与常用的 javac
相比它最大的优势是:可以在 JVM
上直接调用,直接在进程内存中运行编译,速度很快。
上述代码仅仅是一个表达式、并不是完整的 Java 代码,但 janino 提供了方便的 API 能直接编译表达式:
1 | ExpressionEvaluator evaluator = new ExpressionEvaluator(); |
实际上,你也可以手工拼接出如下的类代码,交给 janino 编译,效果是完全相同的:
1 | class MyGeneratedClass { |
最后,依次输入所有参数即可调用刚刚编译的函数:
1 | Object result = evaluator.evaluate(parameterValues); |