Calcite 中新增的 Top-down 优化器

众所周知,Apache Calcite 是为数不多的开源 Volcano/Cascades 查询优化器实现之一,最早脱胎于 Hive 的优化器,后来也被 Flink 等一众项目采用。
但事实上 Calcite 中的 VolcanoPlanner
并非像论文中描述的那样是一个 top-down 优化器。去年阿里云 MaxCompute
团队向 Calcite 提交了 PR,引入了新的 top-down
优化选项,同时也弥补了之前缺失的剪枝、pass-through 等特性。
本文假设读者已经对 Apache Calcite 以及 Volcano/Cascades 优化器的原理比较熟悉。
背景
Calcite 中原来的 VolcanoPlanner
并非对论文的标准实现。具体来说,论文中给出的实现是一个自顶向下(top-down)的递归算法,在每个递归节点上,可以通过某些规则决定
apply 规则的先后顺序。而 Calcite
的实现则是一个全局的优先队列,即 apply
规则的顺序由全局唯一的优先队列控制。(优先队列的实现可参见我之前的文章
Calcite 对 Volcano
优化器优先队列的实现)
这样做的好处是,如果不希望遍历整个搜索空间,该策略能够在给定的有限步数内给出较优解(从我个人经历来看,似乎很少有人这么用)。但代价则是代码逻辑变得十分难懂,也无法进行进行剪枝优化。从使用者的角度看,原本 top-down 优化中 apply rule 一定是先父节点、后子节点,而 Calcite 中的优化则是“随机”发生在 plan tree 的各个节点上,这也给编写 rule 带来了一些麻烦。
2020 年 4 月阿里云 MaxCompute(ODPS)团队提出了 CALCITE-3916:
Support cascades style top-down driven rule
apply,即新增一个真正意义上的 top-down
优化器。这过程中还经历了一些插曲,首次提交的 PR #1950
直接新增了一个 CascadesPlanner
可能因为修改过大并没有被接受,之后又重构了一版 #1991,将同样的功能实现在了
VolcanoPlanner 内部并提供了 TOPDOWN_OPT
选项用于启用或关闭。该功能最终在 2020 年 7 月完成进入主分支。
核心逻辑:TopDownRuleDriver
为了将新旧两种优化器合并在 VolcanoPlanner 中,#1991
抽象出了 RuleDriver 和 RuleQueue 两个类。当
top-down 优化器开启时,VolcanoPlanner
中的以下逻辑会被替换:
RuleDriver:从IterativeRuleDriver替换成TopDownRuleDriverRuleQueue:从IterativeRuleQueue替换成TopDownRuleQueue
其中 TopDownRuleQueue 逻辑很简单:由于 Calcite 是在新
RelNode 生成的时候对其进行匹配的,这里用一个
RelNode -> Deque<VolcanoRuleMatch>
的映射按照匹配的节点存放 rule match
的队列,供以后递归到相应节点的时候再进行 apply。
1 | /** |
我们重点看 TopDownRuleDriver。它的设计参考了 Columbia
优化器,其内部并非是一个简单的递归函数,而是用栈 tasks
模拟了整个 top-down 的过程。
1 | /** |
整个优化过程由下面的循环驱动:不断从栈顶取出 Task 执行,Task 执行中又会产生新的 Task,重复这一过程直到栈为空。本质上这和递归没什么区别。
1 | /** |
可以看到,一切优化都是从一个名为 OptimizeGroup(root) 的
task 开始的。下面我们依次看看有哪些 Task
以及它们分别在干什么。在开始之前先解释一些术语:
| Calcite 的命名 | Columbia 的命名 | 解释 |
|---|---|---|
| RelNode | expression | 一个 plan(或 subplan,下文中不区分 plan 和 subplan) |
| - | multi-expression | 在 VolcanoPlanner 内部时,RelNode 的子节点会被替换成 RelSubset(而非具体的 plan),这时该 RelNode 也就是所谓的 multi-expression |
| RelSet | Group | relational expression 相同的 plan 集合 |
| RelSubset | - | relational expression 和 physical properties 相同的 plan 集合 |
| TransformationRule | transformation rule | 从 logical plan 到 logical plan 的等价变化 |
| ConverterRule | implementation rule | 将 logical plan 转化为 physical plan 的转换规则 |
| RelTrait | physical properties | 物理属性,典型的就是排序(collation)和分布(distribution) |
OptimizeGroup
OptimizeGroup 用于优化一个
RelSubset,类似于 Columbia 中的 O_GROUP。
- 递归优化当前
RelSubset中的每个 physical plan(生成OptimizeInputs) - 递归优化当前
RelSubset中的每个 logical plan(生成OptimizeMExpr)
注意,这里故意先探索 physical plan 再探索 logical plan(即 explore),这是因为搜索 physical plan 的过程中可能生成可行 plan 从而能帮助剪枝。
OptimizeInputs
以及 OptimizeInput1
OptimizeInputs 依次为调用每个子节点的
OptimizeGroup,对应 Columbia 中的
O_INPUTS。
OptimizeInput1 是 OptimizeInputs
在只有一个子节点情况下的简化版本。
OptimizeMExpr
OptimizeMExpr 用于优化一个 logical plan,类似于 Columbia
中的 E_GROUP。这里 MExpr 的命名是借鉴自
Columbia 中的 M_EXPR(multi-expression)
- 依次 explore 每个子节点
RelSubset(生成ExploreInput) - 在当前节点匹配所有可能的规则(生成
ApplyRules)
ExploreInput
ExploreInput 为当前 RelSubset 中的每个
logical plan 生成
OptimizeMExpr。不难看出,它们俩来回调用构成了整个 explore
过程。
ApplyRules 以及
ApplyRule
故名思义 ApplyRules 为当前节点找到所有的 rule match
并生成相应的 ApplyRule,后者 apply rule 生成新的 plan。新
plan 产生后必然会进入某个
RelSubset,进而又会进一步触发后续的优化任务(这部分位于
onProduce):
- 如果产生的是 logical plan 则生成
OptimizeMExpr - 如果产生的是 physical plan 则生成
OptimizeInputs
和上面 OptimizeGroup 做的事情如出一辙。
到此为止,上述这些 task 共同构成了 top-down 优化的递归过程。下图是各个 task 之间的调用关系,蓝色回边意味着递归进入下一层节点。
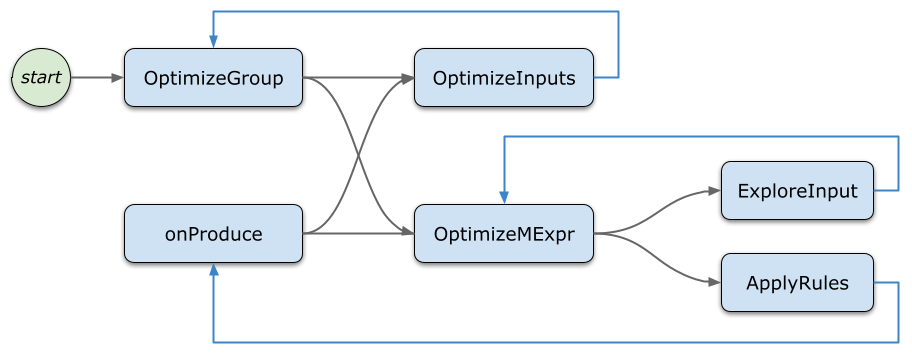
剪枝的实现
Volcano/Cascades 优化器的论文中提到,top-down 相比 bottom-up
的一大优势是可以进行剪枝(pruning 或 branch-and-bound)。在 Calcite
原本的 VolcanoPlanner 中这也是做不到的。
新引入的 top-down 优化器同时也带来了剪枝特性。剪枝的原理可以参见 Columbia 论文 4.3.1 章节,一图以概之:

上图中的 context 在 Calcite 的实现中即是 OptimizeInputs
这个 task。其中,upperBound 在 OptimizeGroup
时传入 RelSubset 最后又传到这里。一旦优化中发现
lowerBound > upperBound,则可以不再优化其他子节点、放弃当前
RelSubset。
1 | /** |
Pruning 发生在 OptimizeInputs 的过程中:
- 初始化:对每个(尚未优化的)子节点通过
RelMetadataQuery中的LowerBoundCost接口获取最低 cost。(LowerBoundCost这个接口需要额外实现,如果没有实现就是 0) - 每当
OptimizeGroup优化完一个子节点,另一个任务CheckInput会用实际的 cost 替代(抬升)之前的 lower bound - 直到完成所有的子节点的
OptimizeGroup
上述 1~3 每个步骤之后都有能出现
lowerBound > upperBound,进而中止当前的
OptimizeInputs 过程,达到剪枝的效果。
Pass-through 和 derive
回忆一下 Volcano/Cascades 优化器中,递归调用的输入参数不仅包括 logical plan,还包括上层所需的 physical properties。二者共同组成了动态规划的最优子结构。
但是 Calcite 原本的 VolcanoPlanner
中并没有向下传递所需的 physical properties,而是通过临时放置一个
AbstractConvertor 作为所需 RelSubset 的
placeholder,在之后 apply rule 的过程中如果能“恰好”产生同一
RelSubset 的 plan,则可能会作为 best
被选出。这一过程中,apply rule 或是算子并不知道上层需要怎样的 physical
properties,因此比较低效。
新增的 top-down 优化器引入了一个新特性,允许算子主动处理上层要求的 physical properties,该特性称为 pass-through。
由于 pass-through 处理的是 physical properties,显然只有物理算子才需要实现 pass-through,相应的接口如下:
1 | /** |
对于 Project、Filter
这样的简单算子,几乎只要直接穿透就可以了。举个稍复杂的例子:
EnumerableHashJoin 算子依次对 probe side 的每一行进行
join,因此不会改变 probe side
的顺序(collation);如果所需的排序键恰好位于
EnumerableHashJoin 的 probe
side,那么可以将其直接向下穿透到 probe side 的子节点上。
有了 pass-through 之后,AbstractConvertor
也就用不着了。相对的,在 top-down 过程中,一旦有新的 physical properties
产生,就会调用下层各个物理算子的 pass-through 接口以及 converter
rule,从中挑选出 best plan。
1 | /** |
为了配合 pass-through,OptimizeGroup 中优化某个
RelSubset 时不仅会检查当前 RelSubset 包含的
plan,实际上它检查的是所属的 RelSet 中所有的 plan。对于其中
physical properties 不同的 plan,它会调用上面的 convert
方法触发 pass-through 以及 converter rule。
最后再说说 derive。我们说过,pass-through 用于自上而下传递所需的 physical properties。但是在某些情况下这还不够。例如考虑 broadcast join 的生成过程,其中 Join 算子的 distribution 需要和其中一个输入节点(例如 TableScan)保持一致,另一边则通过 Exchange(broadcast) 将数据重分布到所有 Join 上。注意这里 Join 算子的 distribution 来自于它的子节点 TableScan,这一自下而上的传递过程就依赖 derive。
DeriveTrait 任务总是在一个 physical plan
生成后被调用,用于调用 derive 接口。如果 derive 产生了新的 trait
则为之生成相应的 RelSubset。
总结
新引入的 top-down 优化器实现了真正的自顶向下搜索。相比 Calcite 原来的
VolcanoPlanner 实现,它具有以下优势:
- 实现更接近论文中的描述,更加简单易懂
- 支持 lower-bound pruning,节约优化时间
- 支持 pass-through,改进 physical properties 相关的优化性能
References
- Apache Calcite - Source Code
- CALCITE-3916: Support cascades style top-down driven rule apply
- CALCITE-3916: Support top-down rule apply and upper bound space pruning #1991
- Efficiency in the Columbia Database Query Optimizer - YONGWEN XU
附件:top_down_trace.zip - 一个简单的两表 Join 的优化过程 trace log,包括优化过程中 plan 的可视化(graphviz + svg)