流计算系统技术对比
前言: 大数据浪潮已经火了十几年,但是流处理领域似乎一直不温不火。直到近两年,从 Confluent(Kafka 背后的商业化公司)上市,到 Snowflake、Databricks 纷纷投资 Streaming,再到 Decodable、Immerok 这些 start-up 公司的涌现。今年 2023 SIGMOD Systems Award 意外颁发给了 Apache Flink,让人不免有些兴奋——流计算的好时代终于到来了吗?
今天从技术的角度聊聊流计算(Streaming)技术。尽管概念上有许多共通之处,例如时间窗口、水位(Watermark)等等,但其实在实现层面上,各个系统几乎都有独特的设计。所谓“存在即合理”,这种系统设计的多样性也正呼应了流计算应用场景的多样性,而并非简单的单一维度上的孰好孰坏。
本文从内部实现的角度,深入对比了市面上常见的流计算系统,包括 Apache Flink、RisingWave、Spark Streaming、ksqlDB 等。希望这篇文章能在技术选型时对你有帮助。
Apache Flink
Flink 诞生之初就提出“流批一体”的构想,即将流计算和批处理使用同一套 Runtime 解决。具体来说,它将批处理看作是流处理的一个特例,二者无非是有界和无界数据流的区别。现在看来,尽管流批一体的设想还没有那么深入人心,但是 Flink 的确凭借它的出色设计,成为了最流行的开源流计算框架。
和众多大数据框架一样,Flink 计算运行在 JVM 之上。Flink 的编程接口叫作 DataStream API,相对地,还有一套批处理接口称为 DataSet API,在这两个编程接口之上,还提供了方便处理关系型数据的 Table API 以及 Flink SQL。上述接口底层共享 Runtime、调度、数据传输层等实现。
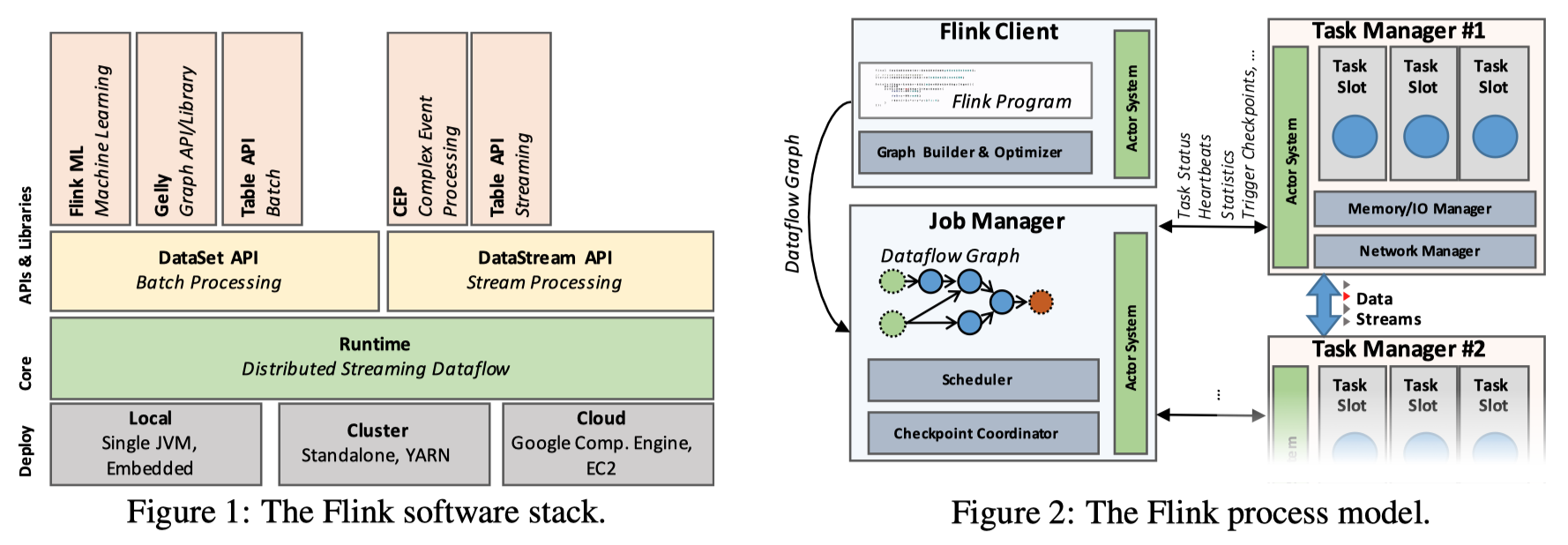
Runtime 部分基本上和常见的 MPP 系统一致:算子以 DAG 方式组织在一起,并通过本地和网络 channel 交换数据,分片并行处理。下文中很多系统也是类似,对于这些共同之处,我们不再赘述。
不同于很多批处理系统标配了列式结构,Flink 内存中的表示是行式结构,即每个 event(或 message)作为一个单元进行计算以及传输时的序列化。为了加速执行,Flink SQL 中使用了 codegen 技术即时生成和编译算子代码,让每行的计算尽可能高效。DataStream API 则只能依赖 JVM 自身的 JIT 来优化用户代码。
状态管理
Flink 是首个引入状态的流计算系统,它将 stateful operator 看作一等公民。今天我们已经很清楚,Streaming 中常用的 Join、聚合等算子都需要状态。状态管理是 Streaming 中不可或缺的一环,它直接决定了故障恢复的设计、一致性语义等等。
Flink 的算子状态保存在算子本地的 RocksDB 实例中(这里仅讨论开源版 Flink 的实现)。RocksDB 的 LSM-Tree 结构使得它能很容易获得一个增量的快照,这是因为当前版本中的大部分 SST 文件和上个版本是重合的,因此拷贝最新快照时只需要拷贝变化的部分即可。Flink 利用了这一特性对本地状态进行 checkpoint,最后将全局 checkpoint 保存在持久化存储上(例如 HDFS 或 S3)。
Flink 1.15 中引入了 Generalized incremental checkpoints 脱离 RocksDB 自行实现了增量 checkpoint,有兴趣的读者可以阅读官方博客。
正确进行 checkpoint 的关键如何获得全局一致的 checkpoint,这一点上 Flink 采用了 Chandy-Lamport 算法,我认为这是 Flink 最大的设计亮点。具体来说,我们从数据流的源头(source)注入一些特殊的消息,称为 Barrier。Barrier 将随着数据流中的其他消息一同流过整个 DAG,每经过一个 stateful operator 就会触发相应相应的算子的 checkpoint 操作。而当 Barrier 流完整个 DAG 时,之前所有这些 checkpoint 就构成了一次一致的全局 checkpoint。
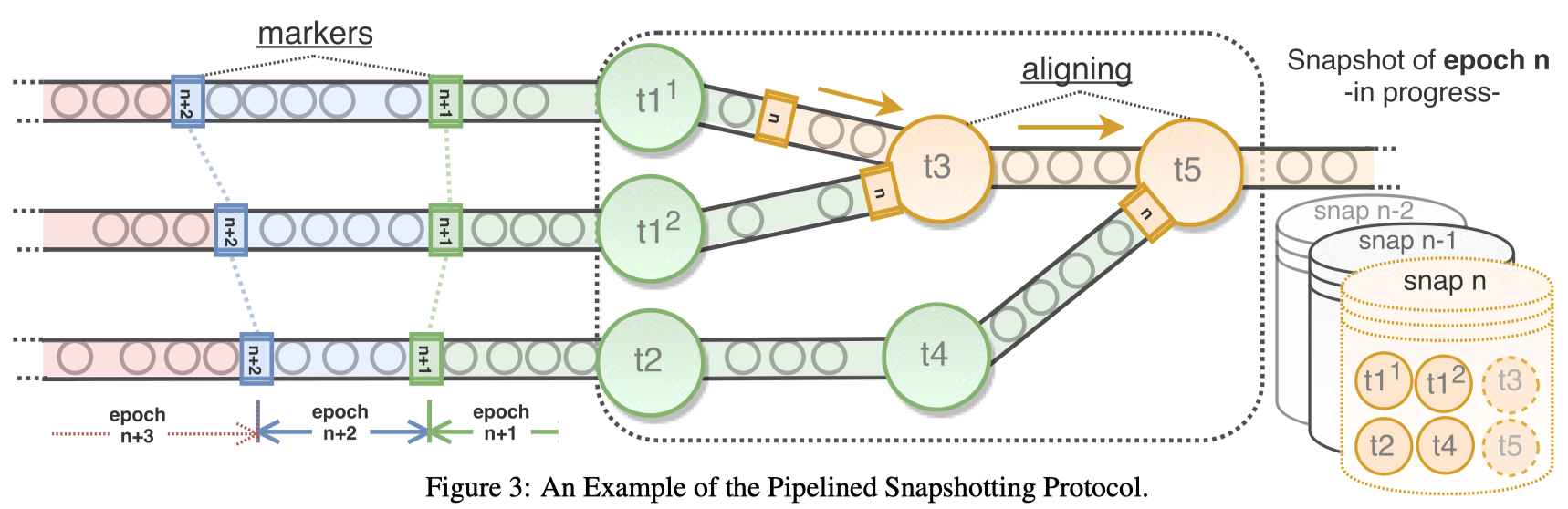
Barrier 在遇到多输入或多输出的算子时会进行对齐(align),这也是它能保证全局一致的关键所在,同时也是它引入的唯一 overhead。考虑到即便没有 Barrier,大多数流计算任务也需要免不了对齐(例如窗口的计算),这个代价并不大。总体来看,Flink 以比较优雅的方式解决了一致性 checkpoint。
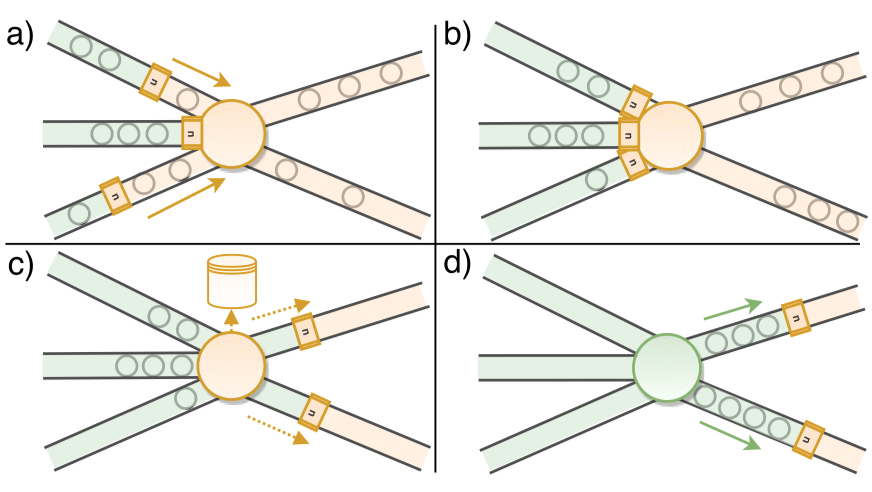
基于上述的 checkpoint 机制,at-least once 以及 exactly-once delivery 都很容易实现。例如,对于 replayable source(例如 Kafka)和 idempotent sink(例如 Redis),唯一需要做的事情就是将 Kafka 当前消费 offset 作为状态的一部分记录在 checkpoint 中,就轻松实现了 exactly-once delivery。对于一些更复杂的情形,一些 Sink 也允许通过两阶段提交(2PC)和外部系统配合实现 exactly-once。
RisingWave
RisingWave 是一个年轻的流计算开源产品,也是我本人现在正在开发的项目。它对自身的定位是流数据库(Streaming Database)而非通用的流计算框架,允许用户使用 SQL 以物化视图的形式定义流计算任务,其设计目标是为了让流计算尽可能简单易上手。它不提供编程 API,如有必要用户可以通过 UDF 引入自定义的代码逻辑。
RisingWave 使用 Rust 语言编写。除了众所周知的内存以及并发安全上的优势,Rust 语言内置的 async 支持以及丰富的第三方库也极大地帮助了我们高效应对流计算这样的 IO 密集场景。RisingWave 的流计算任务由许多个独立的 Actor 构成,Actor 可以看作一个协程,由用户态 Runtime(tokio)进行高效的调度。同时,这也使得算子内部的实现能够采用高效的单线程内存数据结构,例如 Hash Join 所用的哈希表。
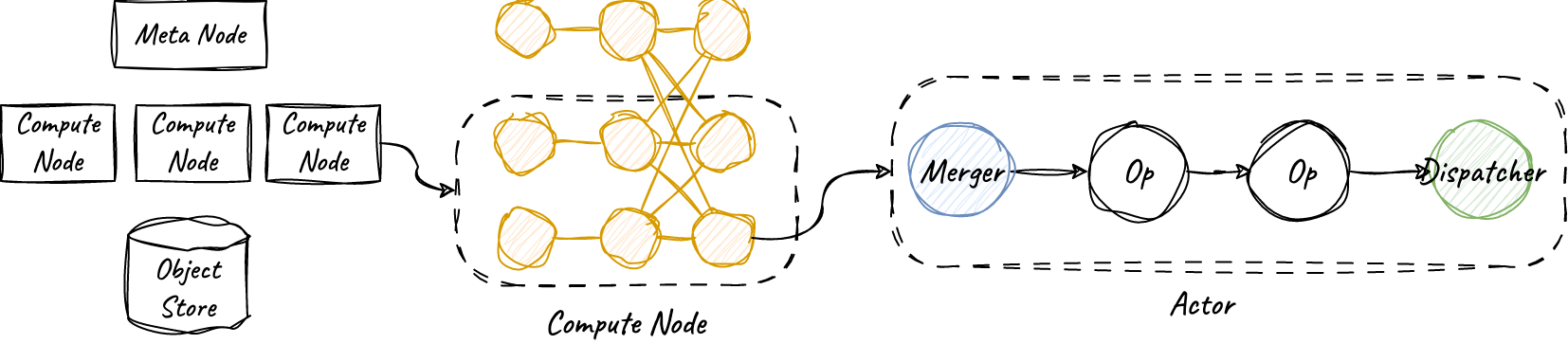
除了流计算,RisingWave 也能像数据库那样直接提供查询能力,而且提供 snapshot read 的正确性保证。具体来说,只要在一个事务中,直接查询物化视图的结果一定与执行其定义 SQL 的结果一致。这很大程度上简化了用户验证 Streaming 任务的正确性。
状态管理
上述的读一致性保证和其内部的 checkpoint 机制密不可分。RisingWave 采用与 Flink 类似的基于 Barrier 的全局一致 checkpoint 机制,但是频率要高得多,默认为 1s 一次(Flink 默认为 30min)。用户的读请求作用于这些 checkpoint 上,因此总是能获得一致的结果。
存储方面,RisingWave 并没有直接使用 RocksDB 之类的开源组件,而是从头打造了一套基于 LSM-Tree 和共享存储的存储引擎。这样做的原因有许多,其中最主要的是为了计算节点能更加轻量地 scale out/in,而不需要像 Flink 那样需要将 RocksDB 的状态文件拷贝到新的节点上。同时,我们也希望能够更好地利用云对象存储的优势,例如 S3 的低成本以及高可靠性。RisingWave 内置存储引擎,并基于此实现了类似数据库的 serving 查询的能力,是它相比其他系统的一大不同。
需要说明的是,Flink 后来引入的 Table Store (Paimon) 存储弥补了 Flink 没有内置表存储的遗憾,但是 Table Store 的主要存储为列式结构,更适合分析型查询。而 RisingWave 的存储引擎为行式,更适合点查这样的 OLTP 查询。
Spark Streaming
Apache Spark 原本被设计为一个批处理引擎。得益于 RDD 的设计,Spark 拥有比 Hadoop MapReduce 更优秀的性能。有兴趣的读者可以看我之前写的《一文读懂 Apache Spark》。
Spark Streaming 使用的技术称为 D-Stream(Discretized Streams)。不同于其他流计算框架会长期运行算子的实例,Spark Streaming 将流数据切分成一个个批处理任务(micro-batch),用一系列的短暂、无状态、确定性的批处理实现流处理。
Spark 2.x 中还引入了一个全新的 Continuous Processing Mode,但似乎不太流行,我们这里不去讨论。
下面两张图描述了 Spark 如何通过 RDD 来实现 micro-batch
的流计算。对于无状态的计算(例如
map),那其实和批计算中没有任何不同。对于有状态的计算(例如聚合),状态的变迁可以视作是
RDD 的迭代,就像右图中最右侧的 counts RDD
那样,它的祖先(lineage)除了计算的上游,还有自己的前一个版本的
RDD。
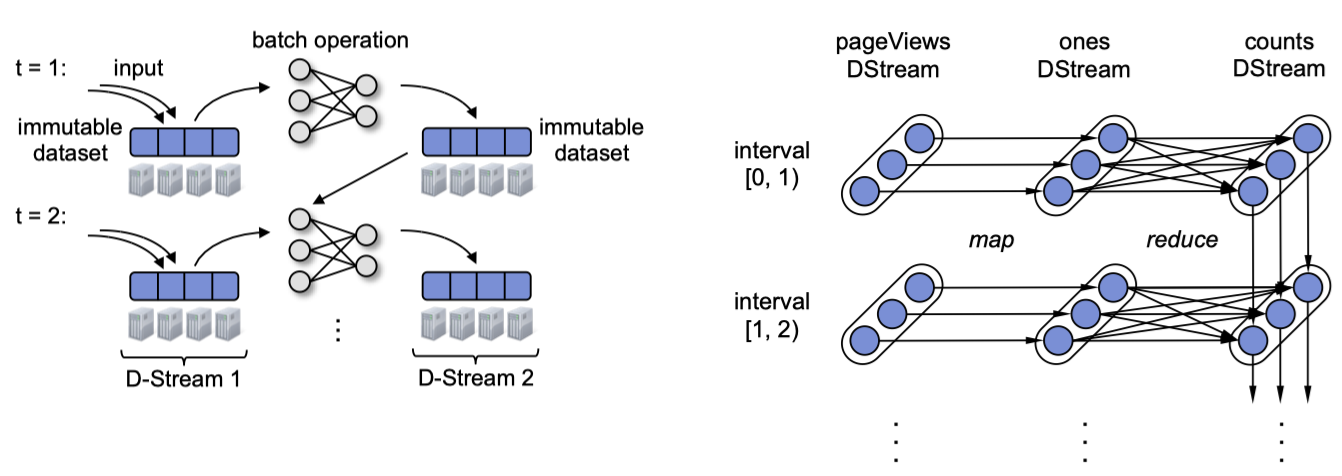
Spark Streaming 非常巧妙地将流计算转换成了基于 RDD
的批处理,也自然地复用了 RDD 的错误容忍机制:只要将失败节点上丢失的 RDD
Partition 重算即可。不过,很显然这里有个问题是 D-Stream RDD
的祖先会不断延长,导致恢复代价变得越来越高,更别说 replayable source
往往是有 retention 限制的。Spark Streaming 通过每隔一段时间调用 D-Stream
RDD 的 checkpoint() 函数将其持久化,以截断祖先链。
事实证明,上述 micro-batch 方案可以达到秒级至分钟级的延迟。Streaming Systems 一书的作者也承认,大多数情况下,这样的延迟已经能满足需求了,“充其量是一个小小的抱怨”。但是也要承认,D-Stream 毕竟只是对 stateful operator 的一种拙劣模仿,在保持设计简洁性的同时,也需要付出更高的代价才能达到相同的计算性能。
Google Dataflow (WindMill)
Google Dataflow,或者它的开源版本 Apache Beam,其实仅仅是一个统一的编程接口,背后支持多种不同的后端 Runtime,包括 Apache Flink、Spark 等。我们这里仅仅探讨 Google 自家的 WindMill 引擎。它更为人熟知的名字是 MillWheel,我对它了解也主要来自于 VLDB'13 的论文 [7]。
MillWheel 的计算和状态管理是完全解藕的。用户编写的算子通过 State API 读写以 Key-Value 模型保存的持久化状态(论文上为 BigTable)。MillWheel 没有全局 checkpoint 的机制,每个算子在向下游发射出数据之前,需要先将状态写入持久化存储,类似数据库的 WAL。这样做的好处是,算子本身保持了无状态的优良特性,可以非常方便地进行故障恢复、调度等,但它的代价是高昂的,所有状态的读写都需要通过 RPC 完成。
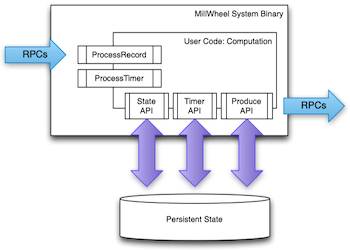
没有全局一致性的 checkpoint 也给实现 exactly-once delivery 带来了挑战。除非算子逻辑具有幂等性,否则算子需要对输入进行去重,防止宕机恢复时有重复消息被处理多次,为此又需要在外部存储上保存一段时间内的 message log。总体来说,该方案消耗了很多无谓的 RPC 代价。
Apache Kafka (ksqlDB)
Kafka 无疑是 Streaming 市场中最大的玩家,它首次将持久性(durability)引入中间件领域,奠定了整个流计算尤其是 exactly-once delivery 的基石。但是之所以放在这里才讲,是因为它的角色主要仍然是 Message Broker,而在计算方面乏善可陈。
ksqlDB (原名 KSQL)是一个构建在 Kafka 上的流处理引擎,由 Confluent 研发。ksqlDB 将流-表对偶性的概念发扬光大,也引入了物化视图这样的概念,允许用户通过 SQL 定义流计算任务。尽管看起来很美好,ksqlDB 设计上有着诸多的限制和妥协,这可能和它轻量级插件的定位有关,但这也让许多用户场景不得不寻求其他的解决方案。
ksqlDB 对于状态的处理就是一个妥协的例子。ksqlDB 利用 Kafka topic 保存状态的 changelog,并借助 RocksDB 将这些 changelog 物化成表,以便算子进行高效地查询(看!一个流-表对偶性的实践)。这样迂回的方式导致 ksqlDB 需要为相同数量的状态消耗了数倍的资源,一不小心还可能引起这样的数据不一致的 bug。
另外,由于 ksqlDB 的任务总是运行在单个 Kafka 节点上(不支持 MPP 那样的 shuffle),无论聚合还是 join 都需要用户小心地确保数据已经按正确的方式分区。必要时,需要创建额外的 repartition 的 topic 才能让跑起来。这也限制了 ksqlDB 对复杂 SQL 的处理能力。
其他
以下这些系统大多已经不再流行,但是它们的设计思路以及取舍仍然值得我们学习。
Flume/FlumeJava 最初由 Google 研发,可能是已知的最早的流计算系统,诞生于 2007 年,最初定位于一套方便开发流计算的编程框架,后来也被用于实现 MillWheel。它的核心是一个叫做 PCollection 的数据模型,它是一个不可变的、有序的、可重复的数据集合,类似于 Spark 的 RDD,而 PTransform 定义了如何对 PCollection 进行转换。Flume 没有内置状态管理,用户需要自己借助外部数据库等方式实现。
Apache Storm 由 Twitter 开源,是另一个早期的流计算系统,它的核心是一个叫作 Tuple 的数据模型,类似 PCollection。相比于其他系统在 exactly-once delivery 上的努力,Storm 选择了追求更快的性能而放弃一致性保证,它仅支持 at-least once 的语义,这让它的实现变得相对简单高效。不令人意外,Storm 也没有内置状态管理,用户需要自己借助外部数据库等方式实现。
Materialize 可能是最早提出 Streaming Database 这一概念的产品。和 RisingWave 类似,它仅提供 SQL 接口,允许用户定义表、物化视图等。Materialize 基于名叫 Differential Dataflow 的 Rust 流计算框架开发,它支持对 Collection 进行各种变换以定义数据流。算子状态保存在内存中的 Arrangement 结构中,这一设计导致它事实上成为了一个单节点的内存数据库,限制了它能处理的数据规模。它也不具备 checkpoint 功能,需要通过重放恢复状态。
总结
| Apache Flink | RisingWave | Spark Streaming | Google Dataflow | Kafka (ksqlDB) | |
|---|---|---|---|---|---|
| 用户接口 | DataStream API + SQL | SQL | DataStream API | Beam API | SQL |
| 数据模型 | Object / Table | Table | Object / Table | Object | Kafka Message |
| 一致性保证 | exactly & at-least once | exactly & at-least once | exactly & at-least once | exactly & at-least once | exactly & at-least once |
| 状态实现 | RocksDB | 内存数据结构 (Cache) + Object Store | RDD (D-Stream) | BigTable | RocksDB |
| Checkpoint 存储 | HDFS | Object Store | HDFS | BigTable | Kafka Topics (changelog) |
| Checkpoint 机制 | Chandy-Lamport | Chandy-Lamport | RDD checkpoint | - | - |
References
- State management in Apache Flink: consistent stateful distributed stream processing
- Apache flink: Stream and batch processing in a single engine
- GitHub - risingwavelabs/risingwave
- Discretized streams: Fault-tolerant streaming computation at scale
- Structured streaming: A declarative api for real-time applications in apache spark
- Dataflow Under the Hood: Understanding Dataflow techniques - Sam McVeety, Ryan Lippert
- Millwheel: Fault-tolerant stream processing at internet scale.
- ksqlDB Performance Guidelines - ksqlDB Documentation
- Streaming Systems - Reuven Lax, Slava Chernyak, and Tyler Akidau
- FlumeJava: Easy, Efficient Data-Parallel Pipelines
- GitHub - MaterializeInc/materialize