JIT 代码生成技术(二)查询编译执行

代码生成(Code Generation)技术广泛应用于现代的数据系统中。代码生成是将用户输入的表达式、查询、存储过程等现场编译成二进制代码再执行,相比解释执行的方式,运行效率要高得多。
上一篇文章 代码生成技术(一)表达式编译 中提到,虽然表面上都叫“代码生成”,但是实际可以分出几种粒度的实现方式,比如表达式的代码生成、查询的代码生成、存储过程的代码生成等。今天我们要讲的是查询级别的代码生成,有时也称作算子间(intra-operator)级别,这也是主流数据系统所用的编译执行方式。
本文主要参考了 HyPer 团队发表在 VLDB'11 的文章 Efficiently Compiling Efficient Query Plans for Modern Hardware。
Volcano 经典执行模型
为什么要用编译执行?编译执行有哪几种实现?这些问题的答案都写在前一篇文章里,还有困惑的同学务必先看完 前一篇文章 再回来。
今天说的主角是查询(Query)的编译执行,在讲它之前,看看经典 Volcano
模型是怎么做的。Volcano
模型十分简单(这也是它流行的主要原因):每个算子需要实现一个
next() 接口,意为返回下一个 Tuple。
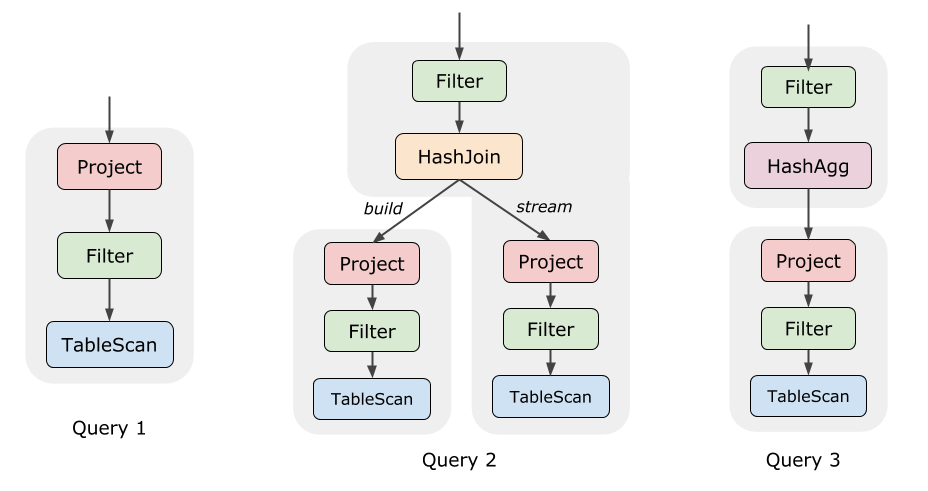
Query 1 是一个很简单的查询,Project 会调用 Filter 的
next() 获得数据,Filter 的 next() 又会调用
TableScan 的 next(),TableScan
读出表中的一行数据并返回。如此往复,直到数据全部处理完。
Query 2 复杂一些,它包含一个 HashJoin。我们知道 HashJoin 的两个子节点是不对称的,一边称为 build-side,另一边称为 probe 或 stream-side。执行时,必须等待 build-side 处理完全部数据、构建出哈希表之后,才能运行 stream-side。
因为这个原因,执行的过程其实被分成了两个阶段(图中浅灰色的背景)。在 Volcano 模型中,这也很容易实现,我们试着写一下 HashJoin 的伪代码:
1 | Row HashJoin::next() { |
这个构建哈希表的过程,我们称为物化(Materialize),意味着 Tuple 不能继续往上传递,而是被暂存到某个 buffer 里。而大多数时候,例如执行 Filter 等算子时,Tuple 是被一路传上去的,这被称为 Pipeline。显然物化的代价是比较高的,我们希望尽可能多的 Pipeline 而避免物化。
Query 3 中的 Aggregate 算子也有类似的情况:在 Aggregate 返回第一条结果之前,我们要把下面所有的数据都聚合完成才行。
我们称 HashJoin、HashAgg 这种打断 Pipeline 的算子为 Pipeline Breaker,它们的存在使得执行过程被分成了不止一个阶段。值得注意的是,这里之所以分成多个阶段,是因为 HashJoin 或 HashAgg 算法本身决定的,跟 Volcano 执行模型无关。
Volcano 的性能问题
Volcano 执行模型胜在简单易懂,在那个硬盘速度跟不上 CPU 的时代,性能方面并不需要考虑太多。然而随着硬件的进步,IO 很多时候已经不再是瓶颈,这时候人们就开始重新审视 Volcano 模型,于是产生了两种改进思路:
- 将 Volcano 迭代模型和向量化模型结合,每次返回一批而不是一个 Tuple;
- 利用代码生成技术,消除迭代计算的性能损耗。
关于这两个方案哪个更优,这里有一篇非常棒的论文做了很详尽的实验和分析。
当然,作为今天的主题,我们只看第二个思路。就像表达式解析执行一样,Volcano 其实是对算子树的解释执行,它也同样存在这些问题:
- 每产生一条结果就要做很多次虚函数调用,消耗了大量的 CPU 时间;
- 过多的函数调用导致不能很好的利用寄存器。
我们来思考一个问题,如果让你去把 Query 1 写成代码来执行,会是什么样的呢?答案非常短,短的令人惊讶:
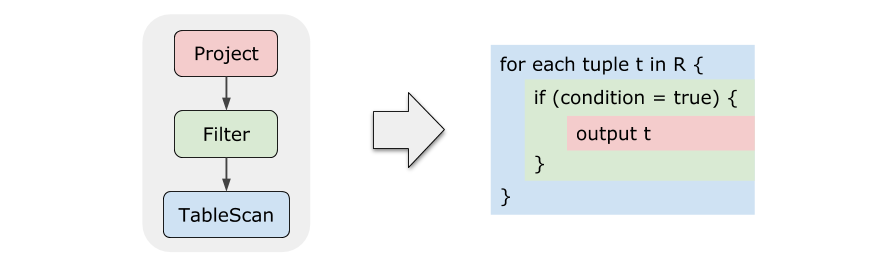
右图中用不同颜色标出了原来的算子,其中 condition = true
是一个表达式,按照上一篇文章讲解的方法就能生成出代码,然后放到这边
if 的条件上即可。
这两个的执行效率应该很容易看出差距吧!生成出的代码完全消除了虚函数调用,而且 Tuple 几乎一直在高速缓存甚至寄存器中。论文中也提到,随便找个本科生手写代码,执行性能都能甩迭代模型几条街。
再看个更复杂的例子找找感觉,以下查询(记作 Query 4)混合了 Join、Aggragate 甚至子查询,之前我们说到,这些算子是 Pipeline Breaker,执行过程被不可避免的分成几个阶段;除此以外,我们希望其他部分尽可能地做到 Pipeline 执行。
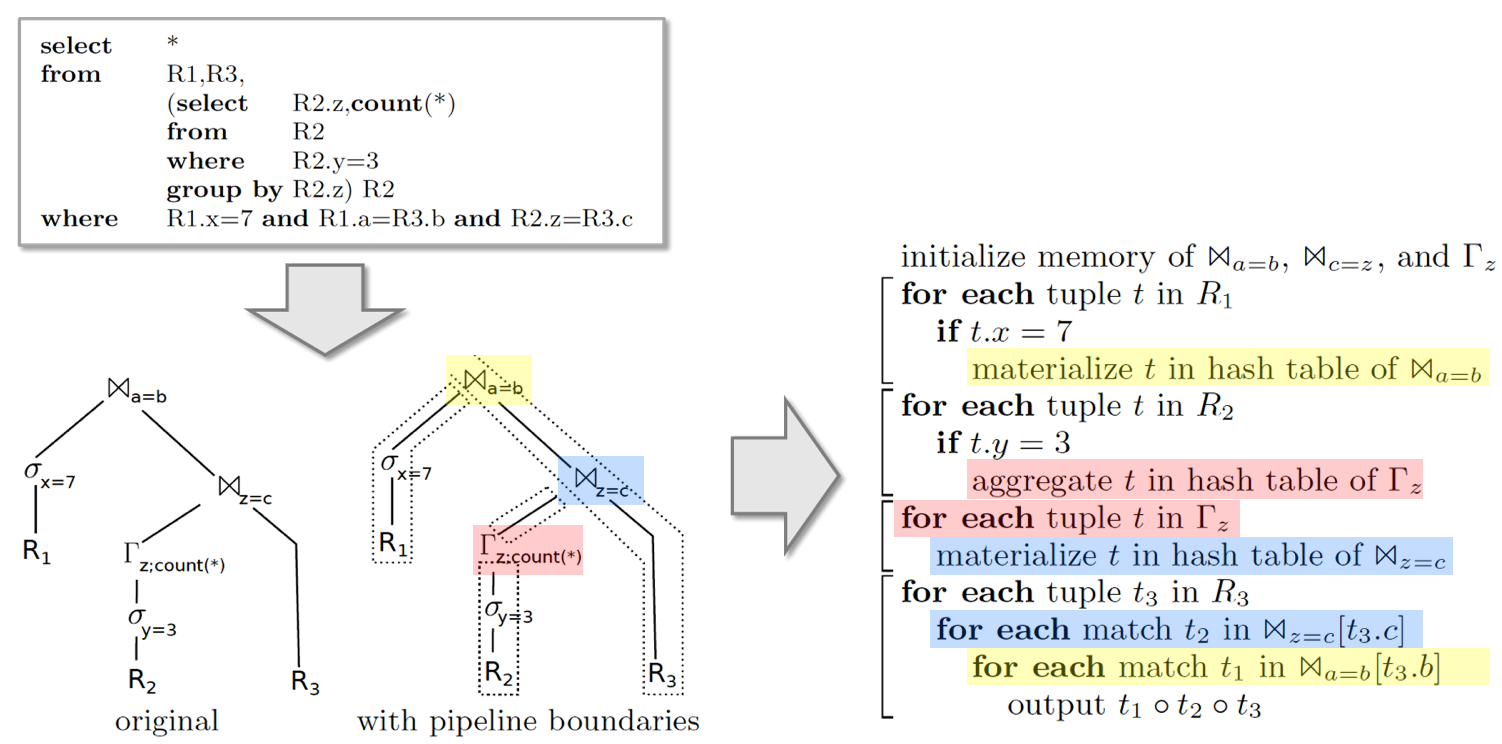
这个例子有点长,但如果你能花上两三分钟看懂它,相信你对代码生成已经有了些直觉上的理解,这对你理解掌握下一章节的内容大有帮助。
图中我用不同颜色出了 HashJoin、HashAgg 三个算子各自的代码,可以看出,它们各自的代码逻辑被“分散”到了不止一处地方,甚至代码中已经很难分辨出各个算子,而是全都融合(Fusion)到一块儿了。
这就是我们想要的结果!好了,下一步终于进入了正题:如何自动生成出这样的代码呢?
很多人有个错觉,以为数据库查询过程那么复杂,生成的代码一定也很复杂吧。其实不然,查询中复杂的部分,例如 HashJoin 中哈希表实现、TableScan 读取数据的实现等,这些并不用生成很多代码,仅仅只是调用现有的函数即可,比如 LLVM IR 可以调用已存在的任何函数。
换个角度看,生成的代码不过是把这些算子的实现以更高效的方式串联在了一起:算子自身逻辑就像齿轮,生成的代码好比连接齿轮的链条。
HyPer 的解决方案
代码生成是个纯粹的工程问题。工程问题没有什么不能解的,难就难在找到其中最漂亮的解。比如现在这个问题,为了编程的优雅,我们希望造一个可扩展的框架:不论哪个算子,只要实现某种接口(就像
Volcano 模型要求实现 next()
接口一样),就能参与到代码生成中。
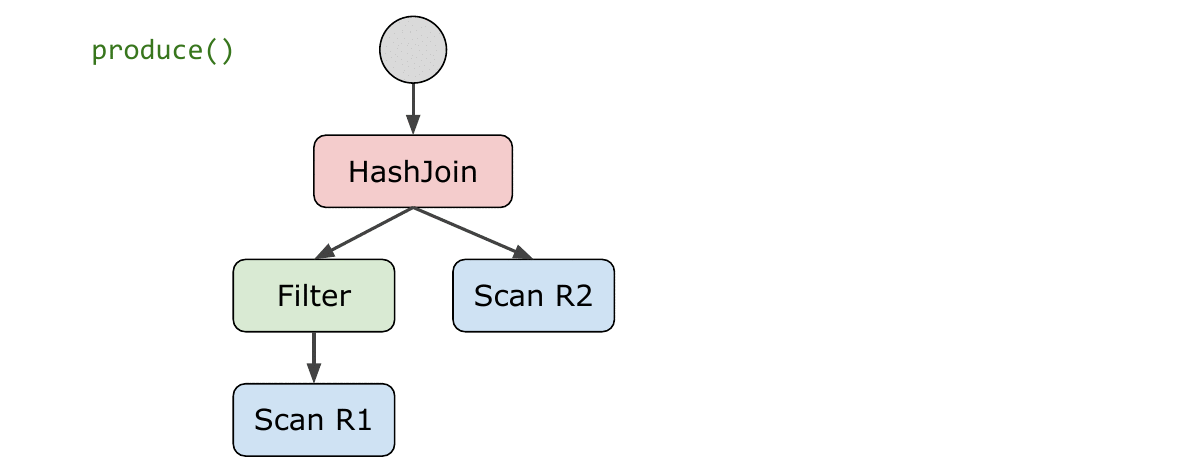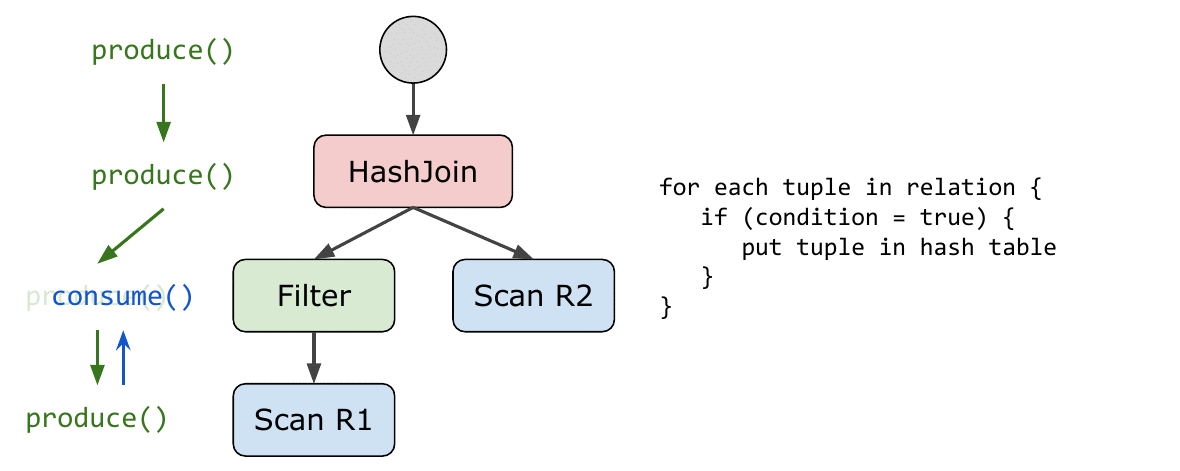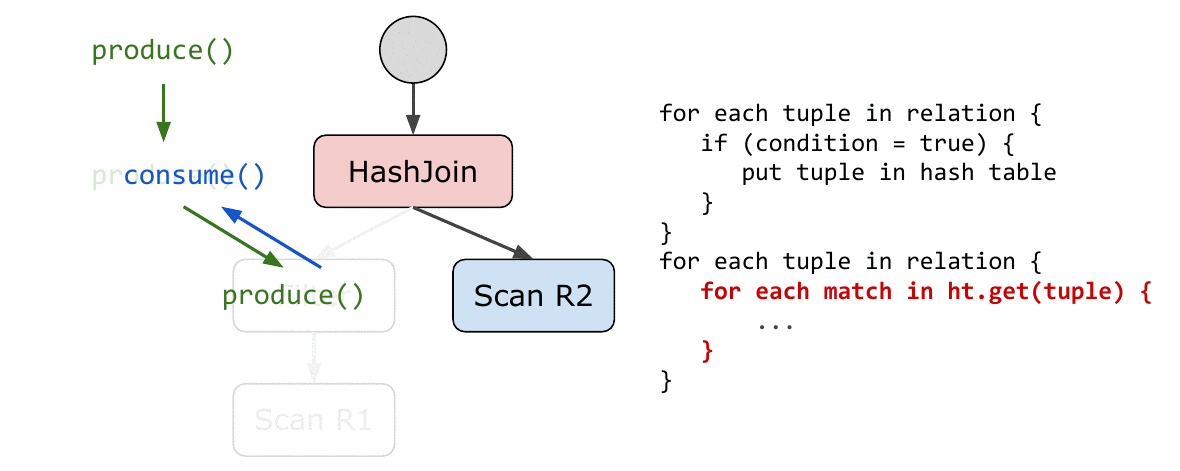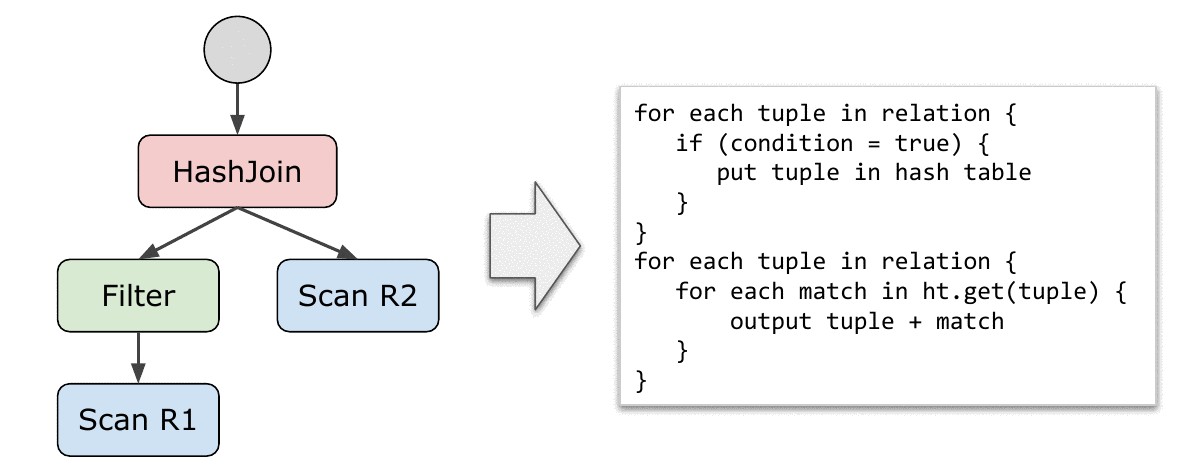
论文中给出的解法可以说是十分优雅了,模型要求所有算子实现以下两个接口函数:
produce()consume(attributes, node)
代码生成的过程总是从调用根节点的 produce() 开始;而
consume()
类似于一个回调函数,当下层的算子完成自己的使命之后,调用上层的
consume() 来消费刚刚产生的
tuples——注意这里并不是真的消费。
用例子来说明。下面是一个伪代码版本的若干算子实现。produce()
和 consume()
返回的类型都是生成的代码片段,这里为了方便演示直接用字符串表示。真实世界中当然要更复杂一些。

表中红色的字符串是生成的代码,黑色的则是 code-gen 本身的代码。回忆一下:代码生成其实就是用各种手段拼出代码(字符串)来,没什么神秘的。
不满足于伪代码的同学可以尝试阅读 HyPer 的 论文(生成 LLVM IR) 或者 Spark SQL 中的 CodeGenerator 实现(生成 Java 代码),后者的代码相对更容易理解些。
思考:这是唯一的解法吗?*
为什么是 produce/consume 呢?是否存在更简单的解呢?这里给出我的推导思路,你可以跳过这一段,毕竟每个人的脑回路是不一样的。
首先,如果只有一个接口函数,不妨叫它
produce(),一定是不够用的。为什么这么说呢?一个函数充其量只能做出类似
DFS 的效果:每个算子只会被经过一次。这对 Query 1
还不是问题,但对于上文中复杂的 Query 4,HashJoin
的两部分代码离得那么远,用 DFS 就很难做到了。
为了处理
HashJoin,我们该增加一个怎样的函数呢?我认为它应该类似于一个回调,比如
Query 4 中,当 DFS 进行到 \(\Join_{a=b}\)
时,我希望通过一种某种方式告诉下面的 \(\sigma_{x=7}\):当你拿到结果后,只要用我传给你的方法去消费这些
Tuples(生成消费这些 Tuples 的代码)。这个方法,不妨叫做
consume()。
顺理成章的,consume() 至少有个参数来传递需要消费的
tuples
有哪些列。另外,还需要一个参数用来指示:调用者是左孩子还是右孩子?这等价于传
this。
以上。因此我倾向于了认为,论文提出的 produce/consume 模式可能是唯一正确的方法,即使存在其他算法,我猜想也是大同小异。