Stable Diffusion 训练指南 (LyCORIS)

Stable Diffusion 文字生成图片的教程已经很多了。这篇文章是讲解如何用 Kohya Trainer 在 Google Colab 上训练一个 LyCORIS 模型。在读之前希望你已经至少玩过 Stable Diffusion。
理论基础
这部分对于理解参数的含义很重要。但你也可以先用默认参数试玩再来阅读这部分。
Stable Diffusion 是一个由文本生成图像(text-to-image)的生成模型(Generative mode)。输入一段文字提示(prompt),输出一段匹配这段文字的图像。
训练过程中,我们先对输入的图像不断添加噪声,如下图所示。如果能把这个过程反过来,由一张完全是噪声的图像,一点点去除噪声得到原始的图像(当然是在模型以及 prompt text 的引导之下),也就完成了 text-to-image 的任务。

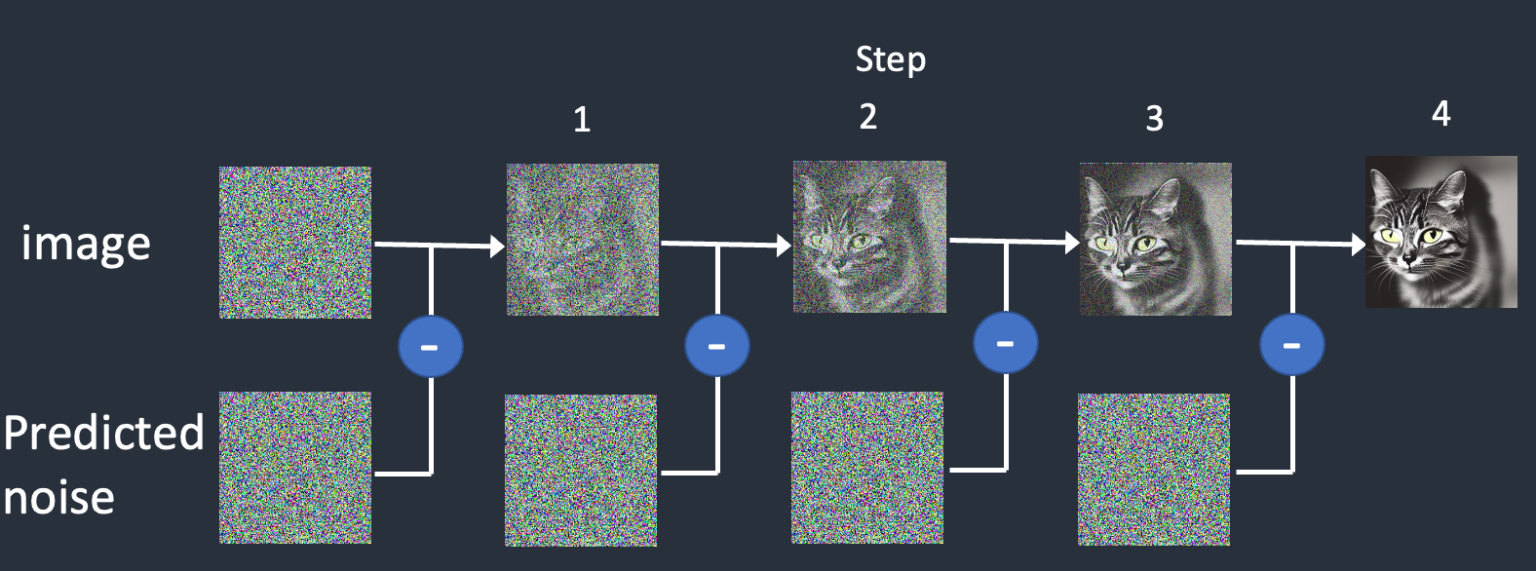
Stable Diffusion 能领先其他模型(比如 DALL-E)的关键在于它并非在直接在像素空间进行上述的 reverse diffusion 过程,而是在潜空间(latent space)。Latent space 大幅地将空间维度缩小到了原来的 1/48。它的工作原理像一个有损压缩算法,既能够压缩也能解压缩,虽然不保证解压结果和压缩前完全一致,但是基本上没差。这个 encode/decode 的过程也是由一个深度学习模型完成,该模型称为 VAE (Variational Autoencoder)。
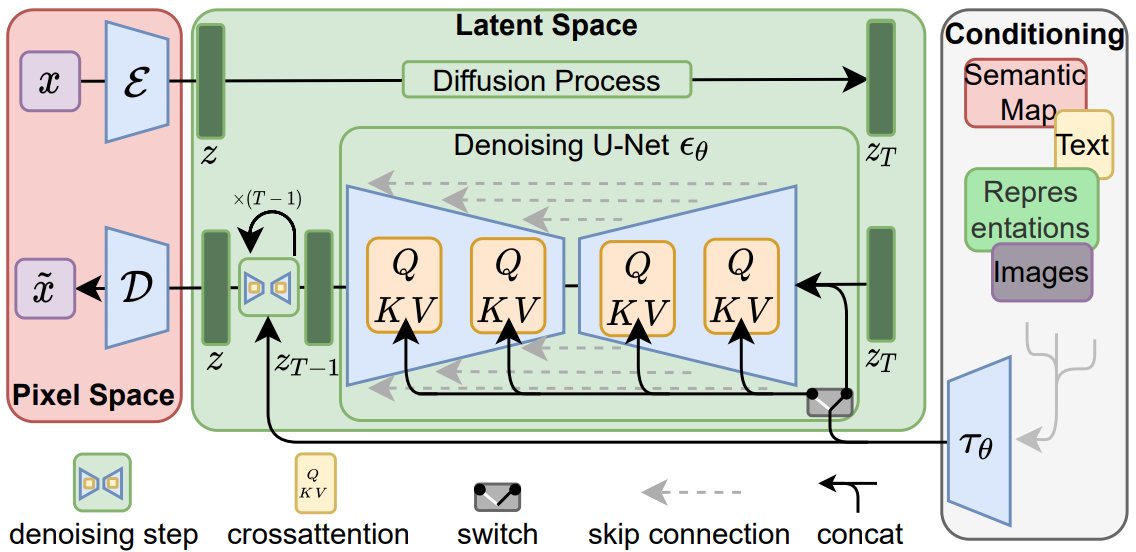
噪音预测器(noise preditctor)由一个 U-Net 模型负责,这也是整个 Stable Diffusion 的最关键的模型。其网络结构包括一堆 ResNet 卷积矩阵和 Cross-Attention 矩阵。Stable Diffusion 包含大约 860M 参数,以 float32 的精度编码大概需要 3.4G 的存储空间。更多关于它的信息可以参考 Stable Diffusion UNET 结构。
最后,还有一个 text embedding 模型,即将一段变长的文字转换成固定维度的向量。Stable Diffusion 1.x 用的是 OpenAI 开源的 ViT-L/14 CLIP 模型,2.x 用的是 OpenClip 模型。
综上所述,Stable Diffusion 中一共有三个模型
- CLIP:用于对 prompt text 进行 embedding 然后输入给 U-Net
- VAE: 将图像从 pixel space encode 到 latent space 以及最后 decode 回来
- U-Net:迭代 denoise 所用的模型,是最关键的模型,我们主要 fine-tune 它
Checkpoint
Checkpoint 就是指将网络参数全部打包保存。Stable Diffusion 的 U-Net 包含约 860M 的参数,以 float32 的精度编码大概需要 3.4G 的存储空间。
LoRA
LoRA 指的是一种对矩阵进行近似数值分解的数学方法,同时也是一种有损压缩,可以大幅降低矩阵的参数数量。LoRA 作用于 U-Net 中的 cross-attention layers(网络结构图中的 QKV 方框)。例如,我们以其中一个矩阵为例,设 fine-tune 之前的原始权重为 \(W\),则这一层的计算可以表达为:
\[ Y = W \cdot X \]
Fine-tune 对 \(W\) 产生了一些微调,这些变化记作 \(W'\)。
\[ Y = (W + W') \cdot X = W \cdot X + W' \cdot X \]
LoRA 所做的事情就是将 \(W'\) 分解:
\[ W' = AB \]
假设 \(W\) 维度为 \((n,m)\),那么 \(A\) 维度为 \((n,dim)\),\(B\) 维度为 \((dim,m)\),不难发现, \(dim\) 取的越小,\(A\) 和 \(B\) 的参数量就越小,相应地, \(|W' - AB|\) 的近似度就越差。
LyCORIS
LyCORIS 是对 LoRA 的增强,其实主要包含两个独立的改进:
- LoCon (Conventional LoRA): LoRA 只调整了 cross-attention layers,LoCon 还用同样的方法调整了 ResNet 矩阵。更多信息参见 LoCon - LoRA for Convolution Network。
- LoHa (LoRA with Hadamard Product): 用 Hadamard Product 替换掉了原方法中的矩阵点乘,理论上在相同的 \(dim\) 下能容纳更多(丢失更少)的信息。该方法来自论文 FedPara Low-Rank Hadamard Product For Communication-Efficient Federated Learning。
LyCORIS 还实现了其他几种对 LoRA 改进的变体,因为很少有人用,这里不展开介绍。
感谢 LoHa,LyCORIS 的模型在 fine-tune 更多层的前提下,反而可以用更小的 \(dim\),因此输出的模型体积也更小。
如果你刚刚开始,建议无脑选择 LyCORIS 模型。本文也将会以 LyCORIS 模型讲解后面的实操步骤。
准备训练集
收集整理需要训练的角色的图片,20 张以上即可。原则是:
- 要能清晰地体现出角色特征,例如训练集要覆盖角色的正脸、侧脸、全身、站坐姿等
- 在保留角色特征的基础上,其他方面尽可能 various,例如不同的角度、场景、风格等
将图片正则化,缩放并裁剪到 512x512 或 512x768 或 768x512 这 3 种尺寸之一,并放置到三个不同的目录中。这步不是必须的,对于实在无法裁剪的部分图片可以跳过,但是 SD 模型本身是用 512x512 图片训练的,使用相同的尺寸能获得更好的效果。裁剪图片可以用 Birme.net。
Stable Diffusion 同一次训练中只能处理一种尺寸的图片(推理也一样)。如果你的图片并非全都是 512x512,Kohya Trainer 中已经自带了 bucketize,长宽比相同的图片会被分类到同一个 bucket 作为同一批次训练。因此,即便你做不到把图片全都统一到 512x512,最好也做到仅有少数几种长宽比。
图片加 Tag 的过程通常是自动标注结合手动筛选,自动标注的过程在 Kohya Trainer 脚本中已经包含,因此现在只要先准备好训练集就行了。
训练
推荐使用 Kohya Trainer。由于咱没有足够好的显卡(训练至少需要 6GB VRAM),无论训练还是推理都是通过 Google Colab 进行。该脚本也很好地适配了 Google Colab,完全做到了一键部署运行。
点击 “Kohya LoRA Dreambooth” 后面的 Open in Colab
按钮开启今天的旅程。
I. Install Kohya Trainer
安装所需的各种依赖。
install_xformers(默认勾选)xformer是 NVIDIA CPU 特有的一个硬件加速库,能够加速计算并减少 VRAM 使用。mount_drive(推荐勾选)映射 Google Drive 到/mount/目录,方便最后保存结果到 Google Drive
II. Pretrained Model Selection
下载 Stable diffusion 基础模型。
Stable Diffusion 2.x 虽然训练步数更多,但是训练集中过滤掉了 NSFW 的图片。注意:SD 1.5 和 2.x 不兼容,但基于 SD1.5 训练的模型可以用在任何一个基于 SD1.5 的 checkpoint 上。而社区的大部分二次元 Checkpoint 模型基于 SD1.5 训练。
如果你在训练二次元 waifu,建议选择基于 SD1.5 的 checkpoint 作为基础模型,例如 Anything V5、Counterfeit V3、AbyssOrangeMix3 等。
2.3. Download Available VAE (Optional)
Stable Diffusion 是自带 VAE 的,这一步的含义是是否要下载一个 VAE 替换原来的 VAE 模型。三次元图更接近 SD 原始训练集,一般不需要。
二次元模型可以选择你的基础模型配套的 VAE,或者选择 notebook 中推荐的 anime.vae。
III. Data Acquisition
把之前准备好的图片放到 train_data_dir(training set)
中。可以有子目录,也可以没有。例如:
1 | $ tree /content/LoRA/train_data |
4.2. Data Annotation
这一步为训练集自动生成 prompt text。脚本的注释中已经给了明确的说明:
- Use BLIP Captioning for: General Images
- Use Waifu Diffusion 1.4 Tagger V2 for: Anime and Manga-style Images
建议从生成的 tags
中移除掉角色自身的特征,比如:long hair, wolf ears, wolf girl, red eyes, brown hair
等。移除掉 tag 代表着将模型将这些特征当作 general
的情况去对待,换句话说,我们希望模型输出的所有图片都带有这些特征。相反,角色本身之外的特征应当用
tag
标识出,比如角色的几件特定穿着(皮肤),相应的,在画图时也可以通过相同的
tag 来触发这些特征。
参数 undesired_tags
可以快速地做到这一点。如果你时间充裕,咱也建议你以把生成的 prompt
下载到本地,逐个人工校对一遍。
如果你想让你的模型拥有一个 tigger word(例如角色的名字),即,仅当 trigger word 出现在 prompt 中时才绘制对应的角色,那么你可以为所有生成的 prompt text 都加上这个 trigger word 并放在最前面。咱觉得这个没什么用,因此跳过。
最终得到的训练集中,每个图片都有一个对应的 .txt 或
.caption 的 prompt
1 | $ tree /content/LoRA/train_data |
建议将这个目录打包存放到本地/Google Drive,方便之后调参。
5.1. Model Config
v2 以及 v_parameterization 需要和当前的 SD
模型相对应。SD 1.5 两个都不需要选。
1 | print("Model Version: Stable Diffusion V1.x") if not v2 else "" |
pretrained_model_name_or_path 是你要 fine-tune
的基础模型。先前在 II. Pretrained Model Selection
步骤中已经下载好了,把它的路径复制过来。vae 也同样。有时候
vae 和 U-Net 可能放在同一个 .safetensor
文件中,这时候两个路径填同一个文件就行了。
5.2. Dataset Config
dataset_repeats 的含义是在每个 epoch
为训练集合内的图片迭代多少次。通常总迭代次数在 1000~3000
次就会有不错的效果,咱的建议每 500 张图片作为一个
epoch,这样就能在训练到 500、1000、1500 ... 3000 的时候分别获得 6
个模型输出,然后根据实际画图效果选取最好的那个。假设一共有 100
张训练图,那么 repeats 就可以设置为 500/100 = 5。
caption_extension 对应 4.2. Data Annotation
中生成的 prompt text 文件名后缀,一般是 .caption 或者
.txt。
resolution 一般选择 512 或 768。如果你之前已经手动裁剪并
resize 过训练集,可以在 Python 代码中设置
bucket_no_upscale = false,防止 512x512 的图片被放大。
shuffle_caption(默认
True)表示自动打乱逗号分隔的所有单词。keep_token
保留前几个标签位置不被 shuffle(默认 0),如果你有 trigger
word,则根据需要调整。
5.3. LoRA and Optimizer Config
network_category 选择 LoCon_Lycoris。
下面 4 个参数可能是争议最多的参数(等号后的数值为咱推荐的数值):
1 | network_dim = 32 |
解释一下:
dim(有时也称为rank)表示 LoRA/LoHa 方法中保留多少维度,\(dim\) 越高表示模型的参数量越大,能承载更丰富的特征,同时也更容易过拟合,通常取值范围 \([1, 64]\),对于 LyCORIS 推荐取值 \(\{8, 16, 32\}\)alpha用于调整模型输出 \(W'\) 的系数,\(W'_{out} = W' \cdot alpha/dim\),\(alpha\) 越高模型越倾向于拟合更多的细节,学习速率也越快,通常取值范围 \([1, dim]\),对于 LyCORIS 推荐取值 \(\{dim/2, dim\}\)network表示作用于 cross-attention 矩阵conv表示作用于 ResNet 卷积矩阵
注意 LyCORIS 和 LoRA 的推荐配置有很大不同。LyCORIS 模型作者推荐
alpha 设置为 1(咱猜测应该是指 \(alpha/dim\) 设置为
1),dimension <= 32(大于 64 的值会导致 $rank = dim^2 $
超过原矩阵维度) 。这篇文章
对 dim 和 rank 的取值做了大量实验,对于
LyCORIS,dim 取值似乎并没有很大的影响。
Optimizer Config
基本上只影响训练速度,建议全部保留默认值。如果有兴趣可以自行搜索
DAdaptation optimizer 的使用,否则就用默认的
AdamW8bit。
1 | optimizer_type = 'AdamW8bit' |
其中
train_text_encoder这一项,按照咱的理解,至少对于 LoRA/LyCORIS 模型是不生效的,在训练的过程中应该都是直接使用了 CLIP 模型的默认参数。但是没有查到相关资料。
5.4. Training Config
num_epochs 控制一共训练多少步骤。上文提到过,图片总数 ×
重复次数(repeats) × epoch 数大约在 1000~3000 之间,这里选择合适的 epoch
数使得总数大于等于 3000。
1 | vae_batch_size |
batch_size 取决于你的 VRAM,在 VRAM 够用(不抛出 CUDA
out-of-memory 错误)的情况下越大越好、训练速度越快。对于 512x512
的图片、16 GB VRAM 的配置,推荐设置
batch_size = 6,其他配置可以自己调整尝试。
1 | mixed_precision = fp16 |
精度保持 fp16 即可。
1 | save_n_epochs_type = save_every_n_epochs |
决定在什么时机保存当前训练的模型状态,因为训练太多次往往会出现过拟合,体现为生成出的图像有明显的风格化(stylish),这时就需要找一个更早些的模型。建议 1 epoch 保存一次。
1 | max_token_length = 225 |
这部分涉及到 CLIP 模型,即 text embedding 所用的模型。
max_token_length指输入 CLIP 进行 text embedding 最大 token 数,常见取值有 \(\{75, 150, 225\}\),一般这几个值都足够用了clip_skip指从后往前跳过的层数,CLIP 模型输出一共有 12 层,越往后的所在层数越高、信息越具体,跳过过于具体的信息可以防止过拟合。更详细的解释参考这个 discussion。经验上,推荐二次元模型选择clip_skip = 2,现实模型选择clip_skip = 1
其他杂项:
lowram:在可以的时候从 VRAM 从卸载掉不必要的参数,节省内存。建议设置为 true。enable_sample_prompt:边训练边测试,个人习惯打开,可以在训练的差不多的时候终止掉。sampler: 和生成图片时的一样含义,影响不是很大,推荐Euler A
如果使用了 enable_sample_prompt = true,记得编辑
/content/LoRA/config/sample_prompt.txt
将其内容调整为需要测试的
prompt。想不出来的话可以从训练集随便挑一个。
5.5. Start Training
之前的步骤生成的配置会保存在
./LoRA/config/dataset_config.toml 和
./LoRA/config/config_file.toml
这两个文件中,开始训练前可以再 review 一遍。
开始训练之后,注意 log 中的 bucket resolution 以及图片数是否符合预期。
1 | number of images (including repeats) |
然后就是等待结果了。
保存现场
最后,无比将整个训练过程保存下来,方便以后改进,包括
/content/LoRA/output: 输出的模型/content/LoRA/config: 训练配置/content/LoRA/train_data: 训练数据/logs/{model}_{timestamp}:日志
推荐阅读
- 官方介绍:How does Stable Diffusion work?
- Paper: High-Resolution Image Synthesis with Latent Diffusion Models
- 文生图模型之Stable Diffusion
- Do Fine-tunning With LoRA (V3)
最后的最后,附上之前训练的模型:Holo (Spice and Wolf) - v3 - Civitai 🥰