从 Weld 论文看执行器的优化技术

Weld 是一个用于数据计算分析的高性能 Runtime(High-performance runtime for data analytics applications),使用 Rust 编写,可以很容易地集成到各种大数据计算框架中,比如 Spark SQL、NumPy & Pandas、TensorFlow 等,带来大幅的性能提升。
除了 Weld 本身的贡献,论文中提到的各种用于执行阶段的优化技术也很有意思,其中的大部分都借鉴自关系型数据库或编译器。本文除了介绍 Weld 之外,也是想对这些技术做个梳理。
本文主要内容来自于 Weld 发表在 VLDB'18 的论文。
整体架构
之前说到,Weld 是一个用于数据计算的 Runtime,它的上层通常是一些计算框架,例如 Spark SQL、NumPy 等。用户用这些计算框架编写程序,这些框架将用户需要的计算翻译成 Weld 中间表示(IR),然后 Weld 对其进行一系列的优化,最后生成代码并编译运行。
做个类比,这就像 LLVM 的工作方式一样:各种语言的编译前端将高级语言翻译成 LLVM IR,LLVM 再对 IR 做一系列的优化,最后再编译成二进制。
虽然都是 IR,但实际上 Weld IR 和 LLVM IR 有很大不同:
- Weld IR 是声明式的:只表达计算流程,不包含具体的实现。比如下面会提到的 Builder,上层不需要指定用什么方式构建数组或是哈希表等数据结构,这些是由 Weld 优化器决定的;
- Weld IR 是 Lazy 的:只有当需要输出结果时,相应的 DAG 计算才会真正开始运行。
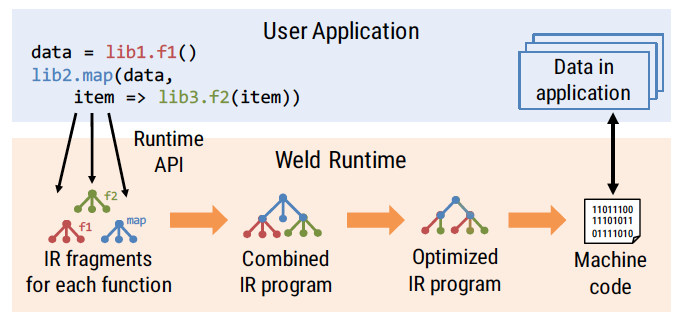
上图是 Weld 的整体工作过程:
- 上层调用 Weld 的 API 输入需要计算的 IR 程序,它会被解析成 AST;
- 当需要执行时,相关的函数 IR 会被拼在一起,方便进行整体优化;
- Weld 优化器使用一系列的启发式规则进行优化,注意结果仍然是 AST;
- 最后生成代码并借助 LLVM 编译成二进制。
Weld 主要由两个部分组成:IR 和 Runtime,接下来我们依次进行介绍。
Weld IR
Weld IR 支持 int、float
等基本数据类型、struct
类型,以及两种容器类型:vec 和
dict,顾名思义,分别是(变长)数组和字典。另外还支持他们的各种组合,就像
JSON 那样。
和数据库的执行器不同,Weld
不考虑数据拉取之类的问题。它假设输入数据都在内存中以数组形式存在,例如:
int[100]、struct{int, float}[100]。
Weld IR 的计算都通过 Builder 和 Merger 来完成,由于 Merger 和 Builder 的接口是一样的,Weld 论文中并没有把二者区分开来。下面我们统称为 Builder。
| Builder | 输入 | 输出 | 备注 |
|---|---|---|---|
vecbuilder[T] |
T |
vec[T] |
通过 append 构建数组 |
dictmerger[K,V,op] |
(K,V) |
dict[K,V] |
通过 put 构建字典 |
merger[T,op] |
T |
T |
聚合计算(例如 add) |
vecmerger[T, op] |
(idx,T) |
vec[T] |
把 T 填在给定位置 idx 上 |
groupbuilder[K,V] |
(K,V) |
dict[K,vec[V]] |
对数据分组 Group by K |
Builder 提供两个接口方法:
merge(b, v):向 Builderb添加新的元素;result(b):拿到b的结果,注意之后不能再添加元素了。
下面是使用 Builder 的例子:

代码中还有个 for,它的语法是
for(vector, builders, (builders, index, elem) => builders),用来并行地对数据做处理——也就是往
Builder 里加元素,这是 Weld 中唯一的计算方式。
for 还可以同时处理多个
Builder,这个特性在优化的时候很有用,可以避免同一个数据扫描多次。
Weld IR 还有些别的特性(比如方便编程的 macro),但不是本文的重点,有兴趣的同学自己看原文吧。
Weld Runtime
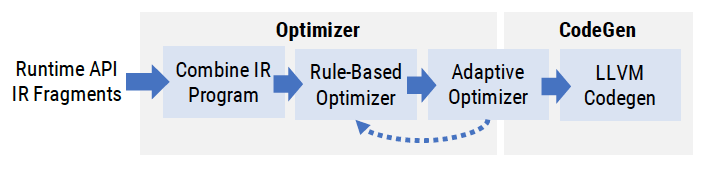
当上层输入 IR 并发出开始计算的指令时,就轮到 Weld Runtime 登场了。在代码生成之前,Weld Runtime 会对 IR 做优化,优化可以分为两种:
- Rule-Based Optimizer (RBO):和我们熟悉的 RBO 优化类似,是基于规则匹配的优化;
- Adaptive Optimizer:运行时 sample 数据,然后决定用哪种算法执行,勉强可以对应 CBO。
为什么不是 CBO?关系型数据库的 CBO 是需要以统计信息为基础的,但是 Weld 作为一个通用的 Runtime,上层框架不一定能提供统计信息(比如 NumPy)。
Weld 应用规则是依次进行的,每次运行一种优化规则,称为一个 pass。Pass 之间会进行剪枝,去掉无用的代码。以下我们逐条看看 Weld 做了哪些优化。
Pipeline
Pipeline 在 OLAP 系统中很常见,最经典的是 HyPer 团队提出的 consume/produce 代码生成机制,可以在代码生成时尽可能生成 Pipeline 的代码。
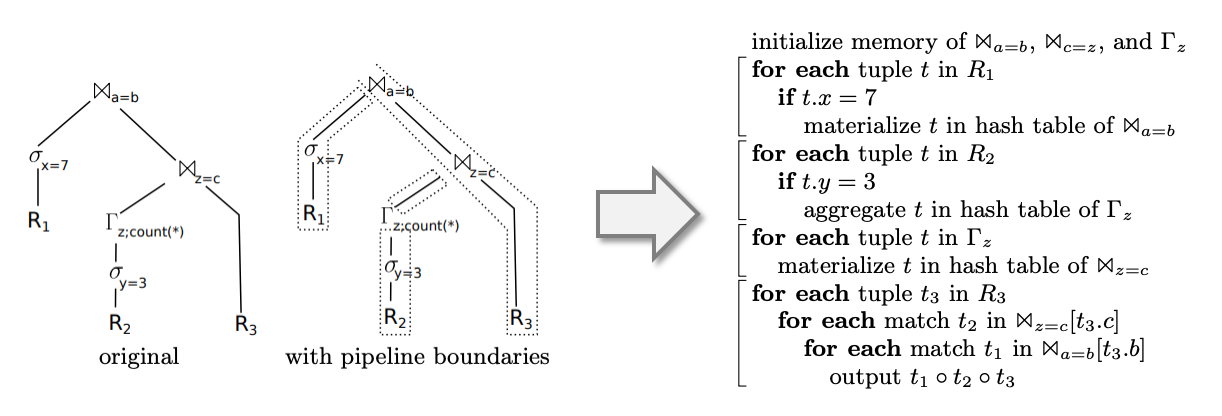
为什么需要 Pipeline?设想一下使用代码生成、但是不使用 Pipeline 会怎么样,那么 \(R_1\) 和 \(\sigma_{x=7}\) 就会分成独立的两步,\(R_1\) (即 TableScan)的结果被物化到内存中,再进行 \(\sigma_{x=7}\)(Filter)。
而 Pipeline 的代码省略了中间的物化,仅仅用了一个 if
就解决了 filter,这个代价要低得多:计算 if
表达式时相关数据基本还在寄存器或 Cache 里,充分利用 Data
Locality,这比去内存取数据快 1~2 个数量级。
Pipeline 优化规则会在 AST 中匹配这样的模式:A 的输出就是 B 的输入,对匹配到的节点应用 pipeline 优化,下面是一个简单例子:

Horizontal Fusion
Fusion 意为把两段代码融合成一段更精炼的代码,刚刚说的 Pipeline 也是一种 Fusion。所谓 Horizontal Fusion 是找出被重复处理的数据,然后将几次处理合在一起。
例如下面图中的 IR,v0 原本被 loop over
了两次,如果把两次循环合成一次,能尽可能利用 Data
Locality,减少一半的内存读取代价。
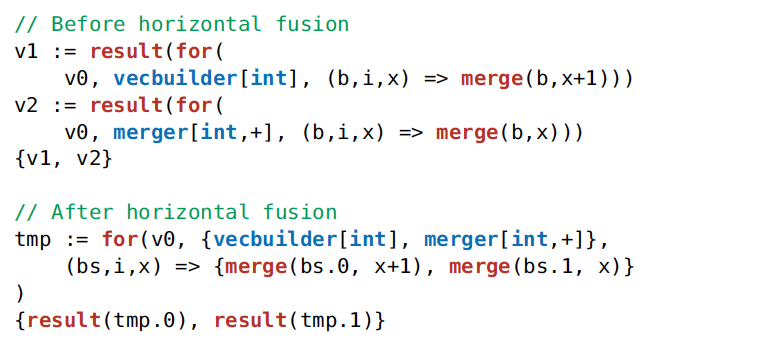
硬要说的话,这个规则与关系代数优化中的 Project Merge 规则最相似。论文中给了一个更好的例子来说明它的用处:像 Pandas 这类的计算框架,由于 API 设计一次只能处理一列,必须借助 Horizontal Fusion 实现一次处理多列。
向量化和 Adaptive 优化
向量化(Vectorization)优化也不是新鲜事,很多编译器(比如 LLVM)都能自动把循环编译成 SIMD 指令,JVM 甚至可以在运行时生成 SIMD 代码。
SIMD 全称是单条指令、多个数据,即用一条指令处理多个数据计算,比如原本计算 4 个整数加法要用 4 次加法指令,用了 SIMD 之后只要 1 次。没错,就这么简单!
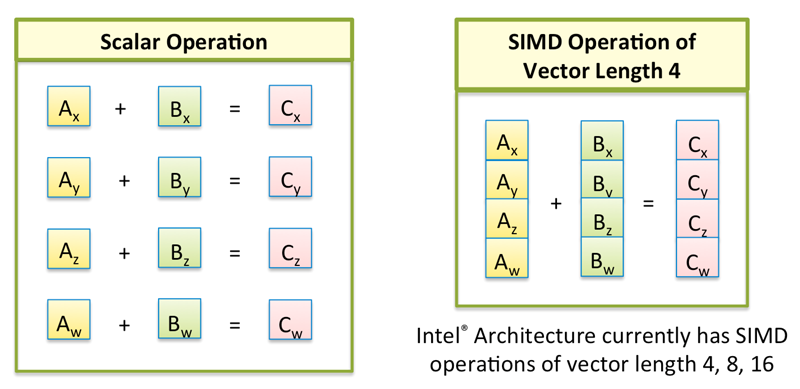
在这个 pass 中仅处理简单的、没有条件分支的 for
循环,如果满足这一条件,优化器会将被循环的数据从 T 转换成
simd[T],最后 code-gen 的时候为其生成 SIMD 代码。
那对于带有条件分支的 for 循环,能否进行向量化呢?答案是,可以,但是不一定有用。
我们先设想一下:对于有条件分支的 for
循环,它向量化之后是什么样的?SIMD 指令本身是没法处理分支的(compare
这种特别简单的除外),如果一定要用 SIMD,可以假设分支条件全都为
true 或 false,最后根据条件表达式的计算结果(true 或
false),利用 select 指令选出相应的结果。
这种方式相比普通的带分支的指令,有得有失:
- 优势:用 SIMD 指令集可以加速计算;
- 劣势:原本只要算一个分支,现在两个分支都要算。
注:另一个优势是,SIMD 去掉了条件跳转,不存在打断 CPU 流水线的问题。但是论文中没有提到这一点,我猜测可能是它的影响因素比较小,或是作者没有找到一个合适的代价计算方式。
论文只给出了对 if(cond, merge(b, body), b)
这样单分支条件的代价建模,有兴趣的同学可以看原论文上的式子。这里只说一个粗糙的结论:当选择率(即进入
if-body 的概率)很小时,有分支的代码更优;当选择率比较大时,SIMD
代码更优。
我们之前说过,Weld 假设上层无法提供统计信息,因而在这一步,由于缺乏关键的选择率信息,它只能采取一种 Adaptive 的思路:同时生成有分支的代码和 SIMD 代码,运行时,首先对输入数据做个 Sample 估算一下选择率,再决定走哪个算法。
选择率(selectivity)这个概念在数据库优化器中也很常用,比如估算 Row Count 时就频繁用到了选择率估计。如果能在优化时直接拿到这个信息,想必不需要这么折腾。
Adaptive Hash Table
Weld 的 dictbuilder 和 groupbuilder
中都需要构建哈希表,这里也有个 trade-off:是用 Partitioned Hash Table
还是 Global Hash Table?
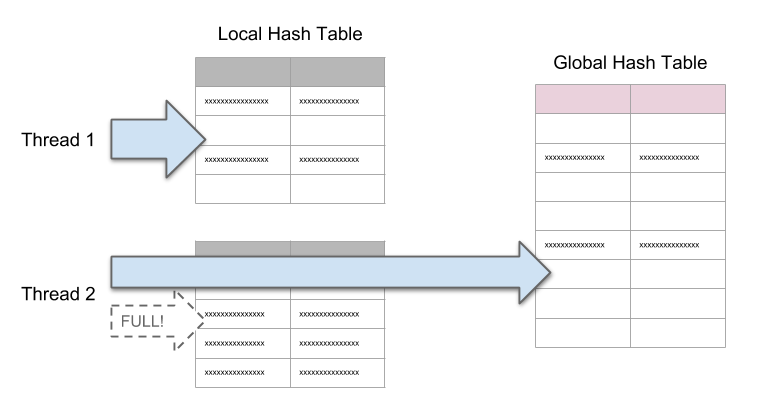
- Partitioned Hash Table 是将 build 过程分成两步,先各个线程本地做 build,最后再 merge 成完整的结果;
- Global Hash Table 只有一张全局的哈希表,通过加锁等方式做了控制并发写入。
一般而言,如果 Group by 的基数(Cardinality)比较小,Partitioned 方式更有优势,因为并发冲突会很多;相反,如果基数很大,Global 更占优势,因为无需再做多一次 merge。
Weld 的做法很巧妙地实现了二者取折中:各线程先写到本地的哈希表,但如果大小超过阈值,就写到全局的哈希表。最后把本地数据再 merge 进全局哈希表。这个实现被它称为 Adaptive Hash Table。
Misc.
Weld 中还有还有一些优化手段,比较简单:
循环展开(Loop Unrolling)是编译器中很常见的优化,如果编译期已知 for 循环的次数很小(例如,对于一个 N*3 的矩阵,第二维度长度仅为 3),就将循环展开,避免条件跳转指令打断 CPU 流水线。
数组预分配(Preallocation)在矩阵运算中也很有用,例如,默认
vecbuiler
的实现是自动生长的动态数组。如果预先知道数组长度,就能避免数组生长的拷贝代价。
评估和总结
下面是 Weld 官网放出的性能评估,对于文中提到的这几个框架,的确做到了可观的性能提升。
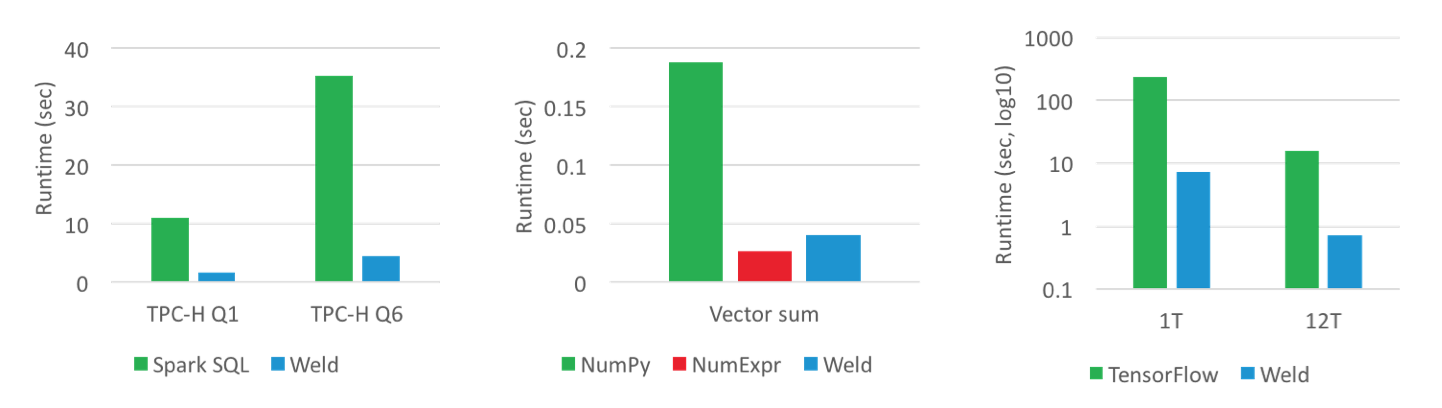
注:这里 TensorFlow 性能是用 CPU 运行的,而非 GPU。
Weld 的最大贡献是抽象出了一个通用的执行器 Runtime。这个抽象的层级要比“代码生成”中的“代码”(比如 LLVM IR)高级(high-level)不少,但又比关系代数或是线性代数低级(low-level),从而有更好的通用性。更可贵的是,Weld IR 仅仅包含 Builder 以及 for、if 这些最基本的语句,极其之简单。
上文提到的很多优化规则,不少来源于编译器或关系型数据库。例如 Pipeline Fusion 的思想,在编译器中其实也有体现——编译器会尽可能连续的利用寄存器、避免 store/load。但是 Weld IR 独特的抽象层级令它能做层级更高的优化,达到和数据库的 Pipeline 一样的效果。